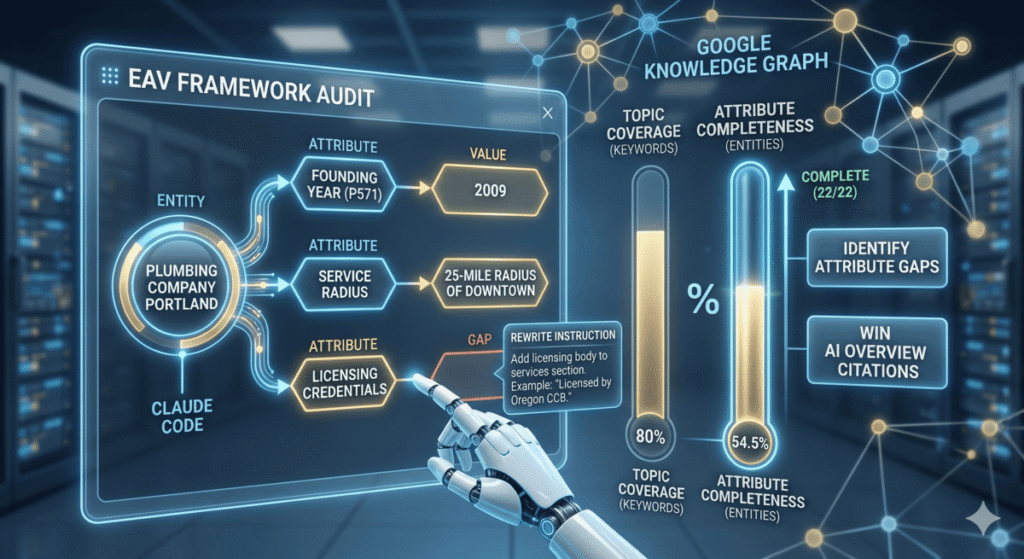
The Entity-Attribute-Value (EAV) framework is a content structuring method that mirrors how Google’s Knowledge Graph stores information. Every entity Google recognizes, whether a brand, a person, a product, or a local service, is described through a set of attributes, each holding a specific value. A page about a plumbing company that covers services, location, and pricing covers topic keywords. A page that also covers founding year, service radius, licensing credentials, team size, and guarantee terms covers attributes. Attribute completeness is what Google uses to decide whether your page is a reliable source about that entity type. This post shows how to run an EAV audit on any draft using Claude Code, cross-reference Wikidata properties for your entity type, identify missing attributes, and store the results in CLAUDE.md so every future draft starts from a complete attribute checklist.
What Is the EAV Framework and Why Does It Matter for SEO?
The EAV model breaks information into three components: an entity (the subject, like “Moz”), an attribute (a characteristic, like “founding year”), and a value (the specific data, like “2004”). This structure is not new to the web. Koray Tugberk Gubur at Holistic SEO traces it to 1970s hospital database systems built by Clement MacDonald, William Stead, and Ed Hammond, a model designed to capture the unpredictable, variable attributes of patient records without creating rigid schema for every possible data type. Google adopted the same architectural logic for the Knowledge Graph because it solves the same problem: how do you store structured facts about millions of different entity types without knowing in advance what attributes each type needs?
In practice, a Google Knowledge Graph entry for an SEO agency might include dozens of attributes: services offered, geographic coverage, founding date, notable clients, certifications, team size, founder name, company type, and links to related entities like tools it uses or competitors it operates alongside. If your content about your SEO agency covers three of those attributes thoroughly and ignores the rest, Google cannot build a confident entity representation from your page. Koray’s implementation of EAV-structured content across a client site produced a 250% organic traffic increase, from 4,000 to more than 10,000 daily clicks in six months, driven by closing attribute gaps, not by adding keyword volume.
Jason Barnard at Kalicube describes this from the other side: Google needs to be able to understand, trust, and present an entity. The understanding layer comes directly from attribute completeness. If your content covers 30% of the attributes Google expects for your entity type, the machine confidence in that entity representation stays low, regardless of how many keywords you rank for. This is the distinction that matters in 2026, and the one that most published EAV content leaves unaddressed. Every article ranking for “entity attribute value SEO” today explains what EAV is. None shows how to audit your existing content against it.
How Does Google’s Knowledge Graph Store Information as EAV Triples?
Google’s Knowledge Graph uses a subject-predicate-object structure that maps directly to Entity-Attribute-Value. The Freebase project that preceded the Knowledge Graph stored facts as triples: (Moz, foundingDate, 2004) is a triple. The predicate “foundingDate” is the attribute. The object “2004” is the value. Wikidata, the open knowledge base that feeds Google’s entity data, exposes this structure publicly through property IDs you can look up and query directly.
The most important Wikidata property IDs for content entities are:
- P31 (instance of): the foundational classification that tells Google what type of thing this entity is
- P279 (subclass of): the parent category, used for entity type inheritance in the graph
- P856 (official website): the canonical URL Google associates with the entity
- P571 (inception): when the entity was founded or created
- P361 (part of): what larger structure this entity belongs to
- P527 (has part): what components or sub-entities this entity contains
- P159 (headquarters location): the geographic anchor for the entity
- P355 (subsidiaries): sub-organizations associated with the entity
- P18 (image): the canonical image Google associates with the entity
For a local business entity, P31 might point to “plumbing contractor” with a specific Wikidata QID. P856 is the official website. P571 is the founding year. P159 is the headquarters city. Each of these maps to content you either do or do not have on your page. When you run an EAV audit, you are checking whether your content supplies values for the full set of attributes Google expects for an entity of that type, not whether you used the right keywords. This is the architectural layer that the entity SEO and Knowledge Graph workflow in this series covers at the macro level. EAV auditing is the content-layer implementation of that architecture, applied to individual pages before they publish.
What Is the Gap Between Topic Coverage and Attribute Completeness?
Topic coverage is the horizontal axis of content strategy: did you write about all the subtopics searchers care about in this space? Attribute completeness is the vertical axis: for the specific entity your page is about, did you supply values for all the attributes that entity type requires? Most content teams optimize for topic coverage and neglect attribute completeness entirely. This is why pages with strong keyword coverage and solid topical authority still fail to appear in AI Overviews for direct entity queries.
Research into AI Overview citation patterns consistently shows that semantic completeness, not keyword density or word count, is the primary differentiator between pages that get cited and pages that do not. Semantic completeness is measured by whether the content answers the full set of questions Google would expect a reliable source about that entity type to address. That set of questions is, at its root, the EAV attribute list for that entity type. A page covering the full expected attribute set has a potential extraction point for every attribute. A page covering half the attributes competes for citations on half as many queries. Attribute gaps are citation gaps, and they compound: a page missing six attributes misses six categories of potential AI-generated traffic.
The June 2025 Knowledge Graph update penalized pages where entity signals were ambiguous: pages that covered enough attributes to be associated with an entity type but not enough to be a confident, specific representation of a particular entity. The update drew a harder line between pages that inform Google about an entity and pages that merely mention it. Attribute completeness is the operating definition of “inform.” The information gain SEO workflow covers how to score a draft against SERP competitors before publishing. EAV auditing is the attribute-completeness complement: where information gain asks “did you cover what the top-ranking pages covered,” EAV asks “did you cover what the entity type requires.”
An example makes this concrete. A page about a SaaS product might have excellent topic coverage: features, pricing, comparisons, use cases, customer reviews. Its attribute completeness might still be 55% if it omits the founding year (P571), the developer team identity (P178), the platform classification (P400: web application), the programming languages used (P277), and the license type (P275). Those attributes are not keywords anyone is searching for directly. But they are the facts Google uses to build a confident entity representation, and their absence keeps the page out of Knowledge Panel features and AI Overview citations for entity-level queries.
How Do You Map Wikidata Properties to Your Content’s Entity Type?
The first step is identifying your page’s primary entity and its Wikidata QID. For a page about a local plumbing company, the primary entity type is “plumbing contractor.” You search Wikidata using the Special:Search function, find the entry that matches your entity type, and note its QID, the alphanumeric ID in the URL (for example, wikidata.org/wiki/Q1357002). That QID number varies by entity; always confirm yours directly at Wikidata rather than assuming the example QIDs in any tutorial apply to your specific use case. Once you have the correct QID, you look at the full list of properties Wikidata uses to describe instances of that type. That list is your attribute checklist. Common entity types and their approximate Wikidata classifications include: software or web application, law firm, news website, local service business, and organization. Each has its own property profile.
Each entity type has a different attribute profile. A law firm’s expected attributes include practice areas (P101), geographic jurisdiction, founding date (P571), number of attorneys, bar association membership, and notable cases. A SaaS product’s expected attributes include developer (P178), platform (P400), programming language (P277), license (P275), and customer segment. A content gap analysis across keyword topics will not surface these differences. Only an attribute-level audit, cross-referenced against the entity type’s Wikidata property set, reveals which specific facts your content is missing.
The manual version of this process is slow: search Wikidata, navigate to the entity type, read the property list, compare against your draft, take notes. The Claude Code version runs the same audit in under three minutes per page, cross-references competitor pages in parallel, and writes the attribute gap report directly to your working file. The topical authority mapping workflow covers the macro-level content structure across a full site. EAV auditing operates at the attribute level within each individual page. Both are necessary, and both write their outputs to CLAUDE.md so they inform every session that follows.
How Do You Build an EAV Audit Workflow Inside Claude Code?
This workflow reads a draft, decomposes it into EAV triples, fetches the Wikidata attribute set for the target entity type, and outputs a gap report with rewrite instructions. Every step runs inside a single Claude Code session without switching to any external app.
Step 1: Read the Draft and Decompose Into EAV Triples
Open Claude Code in your project directory. Claude reads your draft HTML or markdown file directly from the filesystem and extracts every explicit EAV triple it finds:
Read the file at drafts/plumbing-company-portland.md.
Extract every Entity-Attribute-Value triple present in the content.
Format the output as a JSON array: [{"entity": "", "attribute": "", "value": ""}]
Flag any attribute where the value is vague, missing, or implied rather than stated explicitly.Claude returns a structured JSON list of triples. A typical service business page yields 10 to 15 explicit triples, while the full Wikidata property set for that entity type often runs to 20 or more expected attributes. The gap is visible before you open a single competitor page.
Step 2: Fetch the Wikidata Attribute Set via WebFetch MCP
Claude fetches the Wikidata page for the target entity type directly in the same session:
Fetch https://www.wikidata.org/wiki/Q1357002 via WebFetch MCP.
Extract the full list of properties used to describe this entity type.
Return each property as: {"property_id": "P31", "property_label": "instance of", "description": ""}This runs through the same WebFetch MCP call used in the entity salience workflow for Google NLP API calls. Claude fetches the live Wikidata page, parses the property table, and returns the structured attribute list. No manual lookup, no tab switching.
Step 3: Run Parallel Subagents for Competitor Attribute Mapping
Three subagents run simultaneously: one fetches each of the top three competitor pages ranking for your target entity query. Each subagent extracts EAV triples from its assigned page and writes its triple list to a shared working file. What would take five sequential minutes of reading and extracting completes in under two with parallel execution. Claude then compares all three competitor EAV maps against your draft’s triple list. Any attribute that appears in two or more competitor pages but is absent from your draft is flagged as a priority gap.
Step 4: Generate the Gap Report With Rewrite Instructions
Claude outputs a gap report listing each missing attribute, the value your competitors supply for it, and specific rewrite instructions for your draft. Not generic suggestions: exact sentences to add to specific sections. For a plumbing contractor page missing the “service radius” attribute, the output reads: “Add the service radius value to the service area section, paragraph 2. Example: ‘We serve the Portland metro area within a 25-mile radius of downtown.'” That instruction is actionable without any further interpretation.
The entity co-occurrence workflow handles the relationship layer: which entities appear alongside your primary entity across competitor pages. EAV auditing handles the attribute layer within your own page. Both run inside Claude Code and write results to the same CLAUDE.md project memory, so the two audits build on each other rather than running in isolation.
How Do You Store an EAV Map in CLAUDE.md as Persistent Institutional Memory?
After the audit runs, the EAV map writes directly to your project’s CLAUDE.md file under a structured header. The format is consistent across every entity type so Claude can parse it reliably in future sessions:
## EAV Map: Plumbing Contractor Entity (Q1357002)
Last audited: 2026-05-30
### Covered attributes (12/22)
- P31 (instance of): plumbing contractor
- P856 (official website): https://example.com
- P571 (inception): 2009
- P159 (headquarters location): Portland, OR
- [8 more covered attributes]
### Missing attributes (10/22)
- P17 (country): Not stated explicitly
- P527 (has part): Service divisions not described
- P178 (developer/founder): Founder name absent
- [7 more missing attributes]
### Attribute completeness score: 12/22 (54.5%)
### Next scheduled audit: /loop 30d /eav-auditEvery future draft for a client in the same entity category reads this CLAUDE.md entry before generating any content. Claude does not need to re-run the Wikidata lookup. It starts from the existing attribute checklist, checks the new draft against it, and flags any regressions where a previously covered attribute dropped out. This is the pattern the topical authority mapping workflow uses for cluster-level content tracking, applied here at the individual entity attribute level.
The /loop 30d /eav-audit command re-runs the full workflow monthly. Wikidata properties for entity types evolve as Google’s Knowledge Graph expands, and an attribute that was not expected six months ago may be expected now. The loop catches those additions and updates the completeness score automatically. Once you save the workflow as .claude/skills/eav-audit/SKILL.md, invoking it is one command in any future session, not a prompt you reconstruct from memory.
How Does EAV Structure Improve AI Overview Citation Rates?
Google AI Overviews extract passages, not pages. A passage that answers a specific attribute query (“What is the service radius of [company]?”) is extractable only if the content states that attribute explicitly with a clear, specific value. Vague or implied values do not get extracted. Pages structured around EAV triples naturally produce extractable passages because each attribute-value pair forms a self-contained unit that answers a specific question about the entity.
The citation advantage for attribute-complete content follows from this directly. AI Overviews draw from the fullest available source for any given attribute query. A page that explicitly states its service radius, founding year, licensing body, and team structure is cited when a user asks about any of those attributes. A page that implies them or omits them is not. The accumulation of citation opportunities across a full attribute set is what makes EAV-complete pages outperform topically broad pages in AI-generated results.
The passage format matters alongside the attribute content. AI systems favor passages that are self-contained and resolve without surrounding context. Each attribute-value pair functions as an extraction unit on its own. An EAV-structured passage for a product entity might read: “Moz Pro was founded in 2004 by Rand Fishkin and Gillian Muessig in Seattle, Washington. It operates as a web-based SEO software platform offering keyword research, site audits, rank tracking, and backlink analysis as its primary service components. The platform is available under a subscription license with plans starting at $99 per month.” That passage covers five Wikidata attributes in 59 words and is extractable without any surrounding context. The answer engine optimization framework covers the passage structure requirements in detail. EAV auditing ensures the attribute content exists for those passages to be built around. The entity disambiguation workflow ensures Google knows which specific entity each passage is about. The three workflows together form the entity-layer stack that determines how your content performs in AI-generated results.
Frequently Asked Questions
What is the EAV framework in SEO?
The Entity-Attribute-Value framework is a content structuring method that organizes information into three components: the entity (the subject of your page, like a company or product), the attribute (a specific characteristic Google expects for that entity type, like “founding year” or “service radius”), and the value (the specific data that satisfies that attribute, like “2009” or “25-mile radius”). Pages structured around complete EAV coverage are easier for Google to parse, extract, and cite in AI Overviews because they supply the full set of facts the Knowledge Graph expects for that entity type, not just the keywords searchers use to find pages on the topic.
How does the EAV model relate to Google’s Knowledge Graph?
Google’s Knowledge Graph stores facts as subject-predicate-object triples, which is structurally identical to Entity-Attribute-Value. When Google processes a page, it attempts to extract EAV triples and add them to its Knowledge Graph representation of that entity. Pages that supply complete, explicitly stated attribute values make this extraction straightforward. Pages that cover topics without stating specific attribute values force Google to infer, which reduces confidence in the entity representation and lowers the probability of citation in AI Overviews and Knowledge Panels.
What is the difference between topic coverage and attribute completeness?
Topic coverage measures whether you wrote about all the subtopics related to a keyword space. Attribute completeness measures whether you supplied values for all the attributes Google expects for your page’s primary entity type. A page about a law firm might have excellent topic coverage (practice areas, legal process, team bios) but low attribute completeness if it omits the founding year, bar admissions, geographic jurisdiction, and case type specializations that Wikidata uses to describe law firms. Topic coverage gets you ranking visibility. Attribute completeness determines whether you get cited in AI-generated answers, Knowledge Panels, and AI Overview passages.
Which Wikidata property IDs matter most for content SEO?
The highest-priority properties for most content entity types are P31 (instance of, which classifies the entity type), P856 (official website), P571 (inception date), P159 (headquarters location), P361 (part of), and P527 (has part, for describing sub-components or services). For people entities, P106 (occupation) and P17 (country of citizenship) are also critical. These properties represent the attributes Google most frequently uses to anchor an entity in the Knowledge Graph, and they are the ones most commonly missing from content that optimizes for keywords rather than attribute coverage.
How is EAV auditing different from a standard content gap analysis?
A standard content gap analysis compares keyword coverage across competing pages. It answers: what topics do competitors rank for that you do not? An EAV audit compares attribute coverage against what Wikidata defines as the complete attribute set for your entity type. It answers: what characteristics does Google expect a reliable source about this entity type to address, and which ones are missing from your content? The two audits complement each other. Gap analysis finds missing topics. EAV auditing finds missing facts about the entity your page is about. Running both before publishing closes coverage gaps at the topic level and at the entity attribute level simultaneously.
Can the Claude Code EAV audit run on already-published pages?
Yes. For published pages, you feed Claude the URL via WebFetch MCP instead of a local file path. Claude fetches the live page, extracts EAV triples from the rendered content, runs the Wikidata comparison, and outputs the gap report the same way it does for drafts. Running the audit on existing high-priority pages and fixing attribute gaps is often faster than writing new content and improves AI Overview citation rates for pages already generating organic traffic. The CLAUDE.md write works the same way: Claude logs the attribute completeness score and missing attributes, so the next session picks up where the current one left off.
What’s Next
The EAV audit is one layer in a three-part entity workflow. The entity disambiguation workflow handles the prerequisite step: confirming that Google has correctly identified which specific entity your page is about before you audit its attributes. The entity co-occurrence workflow maps which related entities appear alongside your primary entity across competitor pages, covering the relationship layer that EAV auditing does not. Together, entity disambiguation, EAV attribute auditing, and entity co-occurrence mapping form the full semantic entity stack for a page: who the entity is, what attributes define it, and what other entities it belongs alongside in Google’s graph.
If you want the EAV audit skill file, including the full .claude/skills/eav-audit/SKILL.md that runs this workflow as a single slash command and the CLAUDE.md template format, subscribe below. I send the working files for every workflow in this series to the list.