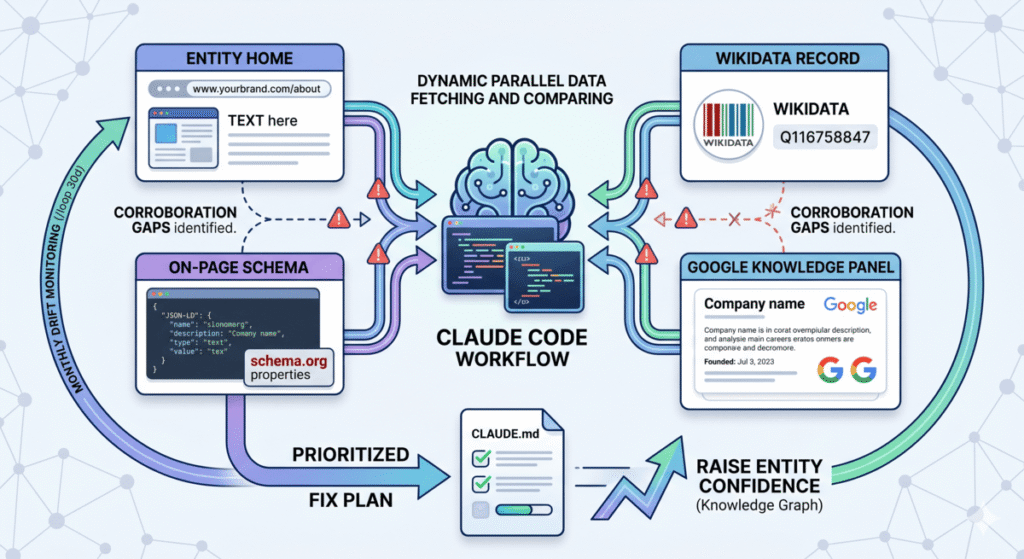
A Knowledge Panel audit compares four signals side by side, your Entity Home, your Wikidata record, your on-page schema, and the Knowledge Panel Google currently displays, then identifies which corroboration gaps are stopping Google from raising its confidence in your entity. The Claude Code workflow below runs that comparison in one session using parallel subagents, validates the gaps against Wikidata QIDs and Schema.org properties, and writes a prioritized fix plan to your CLAUDE.md file. The same skill re-runs every 30 days via /loop so you catch panel drift before it costs you AI Overview citations.
Knowledge Panel work has historically been an agency line item. Kalicube, the firm Jason Barnard founded around this discipline, sells managed Knowledge Panel programs in the four and five-figure range per month. Those programs are valuable, but the audit layer underneath them, the part that surfaces where your corroboration is breaking down, is mostly a structured comparison of data sources. That comparison is exactly what Claude Code is good at when you wire it up correctly.
This post walks through the full audit, the skill file structure, and the specific Wikidata and schema checks that catch the most common entity confidence problems in 2026.
What Is a Knowledge Panel Audit, and Why Are Most “Audits” Surface-Level?
A real Knowledge Panel audit answers four questions in order:
- Does Google have a single, authoritative source it can treat as your Entity Home?
- Do the third-party sources Google checks (Wikipedia, Wikidata, LinkedIn, Crunchbase, news mentions) corroborate the facts on your Entity Home?
- Does your structured data publicly declare those same facts in a machine-readable format Google can ingest without ambiguity?
- Where the answers diverge, which divergences are most likely to suppress your panel or send the wrong facts to AI Overviews and ChatGPT?
Most published Knowledge Panel guides stop at step one. They tell you to add Organization schema, claim your panel through Google Search verification, and submit a Wikidata entry. None of that is wrong, but it skips the comparative layer where the actual lift happens.
Reviewing the top three Google results for “knowledge panel optimization” before writing this post, none included a repeatable side-by-side comparison of Wikipedia, Wikidata, on-page schema, and panel state. None demonstrated how to query the Wikidata API for your QID and validate that your sameAs declarations point to the same canonical entity. None addressed monthly drift monitoring at all. That is the gap this workflow closes.
Why a Knowledge Panel Audit Matters More in 2026 Than It Did in 2024
Three shifts make this audit more valuable than it has ever been:
AI Overviews now cite entities Google recognizes. Google’s stated AI Overview design uses the Knowledge Graph for entity-level summaries. If your brand is not a confidently resolved entity in the Knowledge Graph, your name does not appear in the AI Overview even when your content does. Multiple 2025 studies (including the BrightEdge AI Overview tracking series and the SE Ranking AI Overview report) found that domains with strong entity signals and Knowledge Panels appeared in AI Overview citation sets at materially higher rates than equally ranked competitors without them.
ChatGPT, Claude, and Perplexity train on Wikidata. The Wikidata dump is part of the standard training corpus across major LLMs. A clean Wikidata entry with a stable QID, accurate properties, and well-linked sameAs values means your brand exists inside the model weights as a resolvable entity. A missing or messy Wikidata entry means the model has to reconstruct your identity from scratch every time, which is when hallucinations and competitor confusion show up.
Panel drift is real. Knowledge Panels change. Photos swap out, “people also search for” entries shift to competitors, and key personnel fall out of the panel after staffing changes. Without a monthly comparison, drift is invisible until someone notices the wrong CEO listed.
The Five Corroboration Gaps That Suppress Knowledge Panels
Across client work, five gap categories show up over and over. The audit skill scores each one.
1. The Entity Home Gap
Your Entity Home is the single URL Google treats as the canonical source of truth for your brand. Jason Barnard’s Kalicube process popularized this concept, and it remains the foundation. The gap appears when:
- Your About page, your homepage, and your LinkedIn “About” section state different founding years, founders, or industry classifications
- Multiple pages on your site could plausibly be the Entity Home, and none of them links to Wikidata or your other authority profiles via
sameAs - The page Google appears to be using is not the one you would choose
2. The Wikidata Coverage Gap
Wikidata is a structured knowledge base maintained by the Wikimedia Foundation. Every entity gets a unique persistent identifier called a QID, formatted as Q followed by digits. Anthropic’s QID is Q116758847, verifiable by searching the entity name on wikidata.org. Properties on that entry, founding date, headquarters location, key personnel, official website, are the machine-readable facts Google and LLMs trust at the highest level.
The gap appears when your Wikidata entry exists but is sparse, when its sameAs links do not include your most authoritative profiles, or when there is no Wikidata entry at all and your industry has no obvious referent for “this brand.”
3. The Schema Declaration Gap
Schema.org’s sameAs property is the technical bridge between your site and every external profile that confirms your identity. The gap appears when your Organization or Person schema is present but missing sameAs values, points to inconsistent URLs across pages, or fails to declare key entity attributes like foundingDate, founder, or knowsAbout.
4. The Third-Party Corroboration Gap
Google needs more than your declarations. It needs trusted external sources confirming the same facts. The gap appears when your LinkedIn company page says one founding year, Crunchbase says another, your Wikipedia article (if you have one) says a third, and your About page says a fourth. Google’s confidence drops when sources disagree, and an absent panel is often the result of low confidence rather than active penalty.
5. The AI Citation Resolution Gap
This is the newest of the five. When ChatGPT or Perplexity describes your brand, do they describe it correctly? When you ask Claude “what does [your brand] do,” does the answer match what your Entity Home says, or does it hallucinate a different company with a similar name? If the AI cannot resolve your entity cleanly, your Wikidata and schema declarations are not strong enough.
The Claude Code Knowledge Panel Audit Workflow
The full audit lives in a permanent skill file. Once written, you invoke it on any brand with a single slash command and re-run it monthly. Here is how it works.
Step 1: Save the Skill File
The skill lives at ~/.claude/skills/knowledge-panel-audit/SKILL.md. It is a permanent file, not a one-off prompt. After it is saved, every future audit runs with /knowledge-panel-audit [brand-name].
The skill file defines the inputs (brand name, Entity Home URL, Wikidata QID if known), the outputs (a structured gap report written to CLAUDE.md), and the agent-native steps below.
Step 2: Launch Four Parallel Subagents
The audit pulls four data sources at the same time. Sequential fetches take five minutes. Parallel subagents complete the same work in under two.
- Subagent A: Wikipedia fetch. Uses
WebFetchon the brand’s English Wikipedia page if one exists, extracts the infobox values, the lead paragraph, and the references list. - Subagent B: Wikidata fetch. Queries the Wikidata API directly via
WebFetchonhttps://www.wikidata.org/wiki/Special:EntityData/Q[ID].jsonif the QID is known, or runs a Wikidata search if it is not. Extracts every property, every sameAs link, and the modification timestamp. - Subagent C: On-page schema audit. Fetches the brand’s homepage and About page, extracts all JSON-LD blocks, validates them against Schema.org, and lists every declared property and sameAs URL.
- Subagent D: Knowledge Panel state. Fetches the live Google SERP for the brand name (or uses the Ahrefs SERP overview MCP tool if available) and parses the panel contents that are publicly visible: company description, founding year, founders, related entities, key people.
All four subagents write their structured output to a shared scratch directory. The main agent reads all four and runs the comparison.
Step 3: Run the Five-Gap Comparison
The main agent now has four data sources side by side. It scores each of the five gap categories with a specific question:
- Entity Home gap: Does the schema on the candidate Entity Home declare every fact present in the Wikidata entry? Where they differ, which version is correct?
- Wikidata coverage gap: Which Wikidata properties relevant to this entity type are missing or empty? For an organization, that includes
inception(P571),founded by(P112),headquarters location(P159),official website(P856),industry(P452). - Schema declaration gap: Does the on-page schema sameAs array include the Wikidata URL, the LinkedIn URL, the Crunchbase URL, and the X/Twitter URL? Are any of those URLs inconsistent across pages?
- Third-party corroboration gap: Where Wikipedia, LinkedIn, and Crunchbase report different facts, which fact appears in the Knowledge Panel? That is the version Google currently trusts, and the others are pulling against it.
- AI citation resolution gap: A separate subagent asks Claude itself, “what does [brand] do, who founded it, and when,” then compares the response against the Entity Home. If they diverge, the model does not have a clean entity resolution.
Step 4: Write the Fix Plan to CLAUDE.md
The skill appends a structured fix plan directly to the project’s CLAUDE.md file under a ## Knowledge Panel Audit Results heading. No copy-paste step. The plan includes:
- The ranked list of gaps by likely panel impact
- For each gap, the specific URL to edit, the property to add, or the third-party profile to update
- The JSON-LD diff for any schema changes (current state on the left, recommended state on the right)
- The Wikidata property additions needed, formatted as the exact statement to paste into the Wikidata editor
- Three suggested third-party citation targets (publications, podcasts, industry databases) that would close the corroboration gaps
Because the plan lives in CLAUDE.md, every future Claude Code session for that brand reads it on load. The skill becomes institutional memory, not a one-time deliverable.
Step 5: Schedule Monthly Re-Runs with /loop
Knowledge Panel state changes. Photos swap. “People also search for” drifts. Wikidata edits happen without your knowledge. The skill includes a monitoring mode invoked with:
/loop 30d /knowledge-panel-audit [brand-name]That command tells Claude Code to re-run the full audit every thirty days, compare the new gap report against the previous one stored in CLAUDE.md, and surface any new gaps or drift. The first time a panel field changes, you see it in the next audit instead of three months later.
The Fix Plan in Action: What the Output Actually Looks Like
The skill writes a fix plan in a fixed format so it stays comparable across runs. A truncated example for a hypothetical SaaS brand looks like this:
## Knowledge Panel Audit Results, Acme Analytics (2026-05-18)
Top gap (high impact): Wikidata coverage gap
- Wikidata entry Q[ID] is missing: P571 (inception), P159 (headquarters location), P452 (industry)
- Recommendation: add the three properties with the exact values from the Entity Home About page
- Expected impact: closes the most common reason organization panels remain unstable
Second gap (high impact): Schema declaration gap
- Current Organization schema on /about/ does not include sameAs values for the LinkedIn, Crunchbase, or Wikidata profiles
- Recommendation: add the four sameAs URLs listed below
- Diff: [current JSON-LD] → [recommended JSON-LD]
Third gap (medium impact): Third-party corroboration gap
- LinkedIn lists founding year as 2017
- Crunchbase lists founding year as 2018
- Entity Home About page lists 2017
- Recommendation: update Crunchbase to 2017 (the Entity Home is the source of truth)That format is repeatable, comparable run over run, and immediately actionable. There is no “review your schema” line item. Every recommendation has a specific URL, a specific property, and a specific change.
Why Claude Code, Not ChatGPT, for This Workflow
This is the question that matters most. The audit is not a prompt. It is a coordinated set of tool calls, file writes, and recurring executions. Three things Claude Code does that ChatGPT cannot replicate without rebuilding the entire system around it:
Parallel subagents. The audit needs four independent fetches that all feed the same comparison. In Claude Code, those run as parallel subagents. In ChatGPT, you would run them sequentially, paste the outputs back into context, and lose half the audit time to overhead.
Persistent memory via CLAUDE.md. The fix plan from this month’s audit becomes the baseline for next month’s comparison. CLAUDE.md is loaded automatically every session. ChatGPT memory is not structured for this use case and is not project-scoped.
Skill files as standing capabilities. Once /knowledge-panel-audit is saved, it is a permanent command. Every team member, every client, every audit runs the same way. A ChatGPT prompt is a piece of text you have to remember to paste correctly.
For a deeper take on how the skill file pattern works across SEO use cases, see the related write-up on custom Claude skills for SEO practitioners.
How This Fits With the Broader Semantic SEO Stack
A Knowledge Panel audit is one node in a larger entity SEO program. It pairs with:
- Entity SEO and the Knowledge Graph, which covers the mapping layer between your content and the entities Google has indexed
- Entity disambiguation, which addresses the case where Google or an LLM confuses your brand with a similarly named one
- The EAV framework for entity-attribute-value content structure, which gets your on-page content into the same format Google reads when it populates Knowledge Graph values
- AI search visibility tracking, which closes the loop by measuring whether the corroboration gains actually show up as LLM citations
The Knowledge Panel audit gives the structural layer. The other workflows build the content and signals that fill it.
Frequently Asked Questions
How long does it take to get a Google Knowledge Panel after publishing the audit fixes?
Public guidance from Knowledge Panel specialists and agency case studies points to a typical range of four to twelve weeks for brands with established Wikipedia or Wikidata presence after a clean audit and corresponding fixes. Brands building a panel from scratch typically need three to six months of consistent corroboration before Google’s confidence is high enough to display one. The audit shortens both timelines because it surfaces the specific blockers Google is hitting.
Can you edit your Knowledge Panel directly?
You can suggest edits if you have verified the panel through Google Search by claiming it as the represented entity. Verified parties can update the website link, the description, the logo, and other featured images. Most factual content (founding year, founders, related entities) cannot be edited directly. It is generated from corroborated third-party sources, which is exactly what the audit workflow is designed to fix at the source.
Do you need a Wikipedia article to get a Knowledge Panel?
No. A Wikipedia article accelerates panel acquisition because it is one of Google’s most trusted sources, but it is not required. A complete Wikidata entry combined with strong schema, an Entity Home page, and corroboration across LinkedIn, Crunchbase, and industry databases is sufficient for many B2B and SaaS brands.
What is the difference between a Knowledge Panel and a Google Business Profile?
A Google Business Profile is a Google product you manage directly, primarily for local businesses with a physical location or service area. A Knowledge Panel is generated by Google from the Knowledge Graph and is not directly editable. Many brands have both, and the audit covers the Knowledge Panel side only.
Does a Knowledge Panel actually help with AI Overviews and ChatGPT citations?
Yes, indirectly. A Knowledge Panel is the visible output of strong Knowledge Graph presence. The underlying signals that earn a panel (Wikidata coverage, schema corroboration, third-party validation) are the same signals that determine whether AI Overviews cite your brand by name and whether ChatGPT can describe your brand accurately when asked. Fixing the panel and improving AI citation rates are the same project.
What happens if a Knowledge Panel disappears after a Google update?
Panel removal usually traces back to a sudden drop in corroboration confidence, often triggered by a third-party source change (a key Wikipedia citation getting removed, a major directory delisting the brand, or a major site update breaking schema). The audit workflow catches drift because it stores the previous month’s state in CLAUDE.md and compares each new run against it.
How much should a Knowledge Panel audit and ongoing management cost?
Managed Knowledge Panel programs are typically priced in the four and five-figure monthly range, and that pricing reflects real expertise. For practitioners running the audit in-house, the Claude Code workflow above is a recurring twenty-minute monthly task once the skill file is set up. The two are not mutually exclusive. The audit gives you the visibility to know whether agency work is moving the right signals.
What’s Next
The audit is the diagnostic layer. The next post in the semantic SEO cluster covers the build layer: how to construct the entity schema stack itself (Organization, Person, Product, Service) so the structured data Google reads from your site declares every fact the Wikidata entry expects. Subscribe below to get it Friday.
For more agent-native SEO workflows, subscribe to the email list. New posts every Tuesday and Friday.