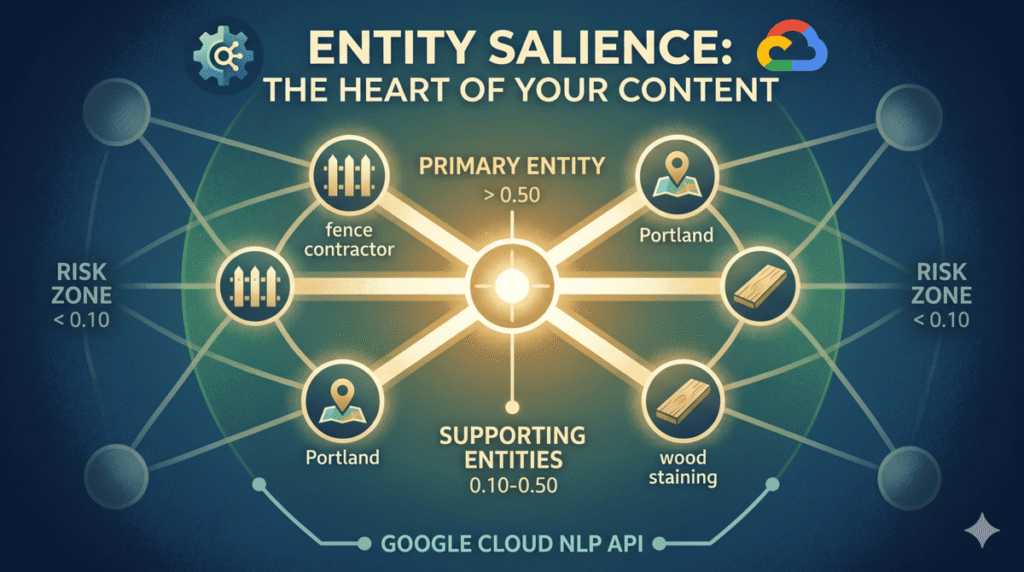
Entity salience is Google’s measure of how central an entity is to a document, expressed as a score from 0.0 to 1.0. A page about fence installation in Portland might score “fence contractor” at 0.58 and “wood staining” at 0.04. The higher the score, the more Google treats that entity as the subject of the document. Pages where the target entity scores below 0.10 are at real risk of being indexed for the wrong topic or failing to rank for entity-based queries entirely.
The Google Cloud Natural Language API returns these scores for free, up to 5,000 requests per month on the free tier. Inside Claude Code, you can run entity salience analysis across an entire site using the Bash tool to call the API, parallel subagents to process multiple pages at once, and CLAUDE.md to persist results across sessions. This post walks through the full workflow, the thresholds that matter, and how to fix the pages that fail.
What is entity salience and why does it affect your rankings?
Salience describes relevance, not frequency. An entity mentioned once in the opening paragraph of a document will often outscore an entity mentioned eight times in the body because Google’s algorithm weights position, surrounding context, and semantic proximity to the document’s central topic.
The distinction matters because most SEO content optimization is still built around keyword frequency, which is a proxy for what Google actually measures. Koray Tugberk Gubur documented the shift toward entity-based content architecture in his semantic content network framework: Google understands pages through entity associations, not keyword density. If your target entity does not score as the primary entity in your content, Google may attribute the page to a different topic than you intended.
After the June 2025 Knowledge Graph update, pages with ambiguous or diluted entity signals saw measurable ranking drops in entity-dependent query categories. The update reinforced that Google treats entity salience as a document-level quality signal, not just a metadata consideration.
This is directly connected to the entity SEO and Knowledge Graph work covered in this series. Mapping which entities you want associated with each page is the strategic layer. Scoring entity salience is the measurement layer that tells you whether your content is actually communicating those associations to Google.
How does the Google Cloud Natural Language API calculate entity salience?
The API analyzes the full text of a document and assigns each detected entity a salience score. Every entity score in a document sums to exactly 1.0. That normalization is the mechanic most SEOs miss.
If your page has 40 detected entities and your target entity scores 0.18, the remaining 39 entities collectively hold 0.82 of the document’s semantic weight. Adding more topics or tangential entities to a page does not dilute keyword density. It directly dilutes entity salience. A focused 900-word page often produces a higher salience score for the primary entity than a 2,500-word page that covers five subtopics.
The API also classifies each entity by type: PERSON, ORGANIZATION, LOCATION, EVENT, WORK_OF_ART, CONSUMER_GOOD, ADDRESS, DATE, NUMBER, or OTHER. An entity typed as OTHER is a signal worth watching. It usually means Google’s Knowledge Graph does not have a strong, unambiguous entry for that entity. If your primary entity consistently returns as OTHER, you have an entity disambiguation problem before you have a salience problem.
Position bias is the third mechanic. Entities introduced in the first two paragraphs of a document consistently receive higher salience scores than entities with equal or greater mention frequency introduced later. Barry Adams documented this in the context of news SEO and accessibility trees, noting that AI crawlers weight early content signals more heavily when building their semantic representations of a document. The same principle applies to standard web content.
The API response also includes a metadata field for each entity. When Google can resolve an entity to a specific Wikipedia or Wikidata entry, the metadata includes that URL along with a Wikipedia MID (Machine ID). An entity with a populated Wikipedia URL in its metadata is one Google can place definitively in the Knowledge Graph. An entity with empty metadata is one where disambiguation risk exists, meaning Google may be uncertain which instance of that entity name your content refers to.
What do entity salience scores actually mean for your content?
Three ranges are worth treating as working thresholds:
A score above 0.50 indicates a primary entity. Google is likely treating this entity as the central subject of the document. This is where you want your target entity to land on pages that carry significant ranking intent for entity-based queries.
A score between 0.10 and 0.50 indicates a supporting entity. The entity is present and semantically meaningful but is not the document’s primary focus. This range is appropriate for entities that contextualize the primary topic without competing with it.
A score below 0.10 is the risk zone. Entities in this range are peripheral. Google may not reliably associate these entities with the document in its Knowledge Graph index. If your target entity scores below 0.10, the content is not communicating the intended topic clearly enough.
These thresholds are working heuristics derived from testing, not official Google documentation. Google has not published specific salience thresholds. The 0.10 floor is consistent with how the API classifies peripheral versus meaningful entity presence across a wide range of content types.
A real API response for a fence contractor page looks like this:
{
"entities": [
{
"name": "fence contractor",
"type": "OTHER",
"salience": 0.5821,
"metadata": {},
"mentions": [...]
},
{
"name": "Portland",
"type": "LOCATION",
"salience": 0.2134,
"metadata": {
"wikipedia_url": "https://en.wikipedia.org/wiki/Portland,_Oregon",
"mid": "/m/0d9jr"
},
"mentions": [...]
},
{
"name": "cedar wood",
"type": "CONSUMER_GOOD",
"salience": 0.0891,
"metadata": {},
"mentions": [...]
}
]
}In this example, “fence contractor” scores as the primary entity but is typed as OTHER with no Wikipedia metadata. That combination tells you two things: the content is communicating the right topic, but Google lacks a clean Knowledge Graph entry for “fence contractor” as a defined entity class. The fix is adding schema markup and entity disambiguation signals, covered in the topical authority mapping workflow. Portland resolves cleanly to a Wikipedia entry, which is the behavior you want for location entities on local service pages.
How do you set up the Google Cloud Natural Language API?
The free tier covers 5,000 analyzeEntities calls per month, which is enough to audit most sites without spending anything. Go to the Google Cloud Console, enable the Natural Language API, and create an API key under Credentials. Store the key as an environment variable on your machine named GOOGLE_NLP_KEY. Do not paste it directly into Claude Code sessions.
Add this to your CLAUDE.md file for the project so Claude Code can reference it across sessions:
## NLP API Configuration
- API key: stored as GOOGLE_NLP_KEY environment variable
- Free tier: 5,000 requests/month
- Endpoint: https://language.googleapis.com/v1/documents:analyzeEntities
- Last audit: [date]
## Entity Salience Audit Targets
- https://yoursite.com/page-1 | Target entity: [entity name]
- https://yoursite.com/page-2 | Target entity: [entity name]
- https://yoursite.com/page-3 | Target entity: [entity name]How do you run entity salience analysis inside Claude Code?
The workflow runs inside a Claude Code session. Claude reads the target URLs from CLAUDE.md, fetches each page, calls the API, and writes a structured report back to CLAUDE.md. No third-party SEO tool required.
Open a Claude Code session and start with this instruction:
Read CLAUDE.md to get the list of Entity Salience Audit Targets and the target entity for each URL.
For each URL, use WebFetch to retrieve the page content. Strip all HTML tags and extract the plain text body. Then use the Bash tool to call the Google Natural Language API with this command, substituting the page text:
curl -s -X POST \
"https://language.googleapis.com/v1/documents:analyzeEntities?key=$GOOGLE_NLP_KEY" \
-H "Content-Type: application/json" \
-d '{
"document": {
"type": "PLAIN_TEXT",
"content": "PAGE_TEXT_HERE"
},
"encodingType": "UTF8"
}'
Parse the JSON response. For each URL, record:
1. Target entity name, salience score, entity type, and Wikipedia URL (if present in metadata)
2. Top 5 entities by salience score with their types
3. Status: PASS if target entity salience is above 0.10, FLAG if below
Write the full report to CLAUDE.md under a new section: ## Entity Salience Report [today's date]For long page content, the Bash command needs the text escaped properly. Claude Code handles this automatically when you include the extraction and escaping step as part of the instruction. If the page content is large, instruct Claude to truncate to the first 10,000 characters, which is sufficient for salience analysis on standard web pages and stays within the API’s free-tier payload limits.
The output in CLAUDE.md will look like this:
## Entity Salience Report 2026-05-13
### /services/fence-installation-portland/
- Target entity: fence contractor | Score: 0.58 | Type: OTHER | Wikipedia: none
- Status: PASS
- Top 5 entities: fence contractor (0.58), Portland (0.21), cedar wood (0.09), installation cost (0.06), permit requirements (0.04)
### /blog/wood-fence-vs-vinyl-fence/
- Target entity: wood fence | Score: 0.07 | Type: OTHER | Wikipedia: none
- Status: FLAG (score below 0.10)
- Top 5 entities: vinyl fence (0.34), fence materials (0.22), maintenance cost (0.18), wood fence (0.07), homeowner (0.06)
- Note: vinyl fence is outscoring the target entity. Page may be indexed primarily for vinyl fence queries.
### /about/
- Target entity: [company name] | Score: 0.44 | Type: ORGANIZATION | Wikipedia: none
- Status: PASSHow do you analyze multiple pages at once using parallel subagents?
Processing pages sequentially works for small audits. For anything above 10 pages, parallel subagents cut the time significantly. Claude Code can run multiple independent analysis tasks at the same time, with each subagent handling one URL.
The instruction for parallel processing is:
Read all Entity Salience Audit Targets from CLAUDE.md.
Process all URLs simultaneously by running each as a parallel task. Each parallel task should:
1. Fetch the URL using WebFetch
2. Extract plain text
3. Call the Google NLP API via Bash
4. Parse the response and extract: target entity score, entity type, Wikipedia URL, top 5 entities
5. Return a structured result
After all parallel tasks complete, collate the results. Identify all pages with FLAG status (target entity below 0.10). Write the full consolidated report to CLAUDE.md.
Also write a priority fix list: pages ordered by urgency (lowest salience score first), with the competing entities that are outscoring the target entity on each page.On a 20-page audit, parallel subagents complete the full analysis in roughly the same time a sequential workflow takes for 5 pages. The CLAUDE.md output becomes the canonical record of your site’s entity salience state, which carries forward into future sessions without re-running the analysis.
This is the workflow Claude Code enables that no chat interface replicates. A ChatGPT session cannot call the Google NLP API via shell commands, cannot spawn parallel tasks for multiple URLs, cannot write a persistent report to a file your next session will read, and cannot be scheduled to re-run monthly. Each of those capabilities is doing real work in this workflow.
How do you fix low entity salience scores?
The fixes are about content structure, not keyword repetition. Adding the target entity phrase five more times will increase mention count but may also increase the total entity count and dilute salience further.
The most reliable fixes are:
Move the target entity into the first 75 words. Position bias is real. Rewrite the opening paragraph so the primary entity is named explicitly and in a context that establishes it as the document’s subject, not just a topic mentioned in passing.
Reduce competing entity clutter. If your wood fence page mentions vinyl, aluminum, chain link, composite, and bamboo as comparison points, each of those is an entity competing for salience weight. Consider whether the comparison framing serves the page’s ranking goal or undermines it. A page that establishes wood fence as the primary focus and treats alternatives as brief context will usually outscore a comprehensive comparison page on entity salience for the wood fence target.
Use Claude Code to rewrite specific passages once you have the FLAG list. The instruction is direct:
Read the Entity Salience Report from CLAUDE.md.
For each flagged page, fetch the current page content using WebFetch. Identify the competing entities that are outscoring the target entity.
Rewrite the opening two paragraphs to:
1. Name the target entity in the first sentence
2. Establish the target entity as the document's primary subject before introducing any competing entities
3. Reduce peripheral entity mentions in the opening section
Do not add keyword stuffing. The goal is entity clarity, not density. Present the rewritten paragraphs for review before making any file changes.Review the rewrites before publishing. The goal is to establish clear entity priority in the document’s opening, not to strip all context from the page. Pages that perform well on entity salience tend to open with a clear statement of what the page is about, which is also good writing practice for humans.
How do you make entity salience monitoring recurring with /loop?
Save the entity salience workflow as a skill file at .claude/skills/entity-salience-audit.md. The skill file contains the full set of instructions from the workflow above, including the CLAUDE.md reading step, parallel API calls, report writing, and flag identification.
To run the audit on demand:
/entity-salience-auditTo run it on a monthly schedule in Claude Code’s loop mode:
/loop 30d /entity-salience-auditMonthly monitoring lets you track two things: whether content updates on flagged pages improved salience scores, and whether new content published during the month introduced pages with salience problems before they compound into ranking issues. The CLAUDE.md report history builds a dated record of your site’s entity health over time.
For client sites managed through an agency CLAUDE.md setup, you can store each client’s URLs and target entities in separate sections and run the audit across all clients in one session using the parallel subagent approach.
What are the most common entity salience mistakes SEOs make?
The most common problem is entity dilution through comprehensiveness. Longer pages that cover a topic from every angle often score lower on salience for the primary entity than shorter, focused pages. This conflicts with the instinct to write exhaustive content. The resolution is to create separate pages for each entity you want to rank for, rather than cramming multiple entity targets into one page.
The second mistake is treating salience and keyword density as the same thing. They measure different aspects of document relevance. A page can have high keyword density for a term and low entity salience for that same entity if the surrounding context establishes other entities as more central. The API is measuring semantic weight, not string frequency.
The third mistake is ignoring entity type classifications. When your target entity consistently returns as OTHER with no Wikipedia metadata, the salience score problem is secondary. The primary problem is that Google cannot place your entity in the Knowledge Graph with confidence. Addressing that through sameAs schema, Wikipedia article creation or citation building, and Wikidata entries will improve the API’s ability to classify your entity correctly, which in turn improves how Google represents it in search.
The fourth mistake is running a one-time audit and treating it as permanent. Entity salience scores change when content changes. New internal links pointing to a page shift its perceived topic. New sections added to a page introduce new entities. The /loop workflow exists because entity health is a moving target, not a one-time checkbox.
For the full semantic SEO picture, this workflow connects directly to the Claude for SEO framework and the semantic internal linking work covered in earlier posts. Entity salience tells you what your content is communicating. Internal link architecture tells you how your site’s entity associations are distributed across pages. Both signals feed into how Google builds its understanding of your site’s topical authority. The logical next step after running a salience audit is finding which entity relationships your page is missing compared to the pages that outrank it — that is exactly what the entity co-occurrence gap analysis workflow covers.
Frequently Asked Questions
What is a good entity salience score for SEO?
A score above 0.50 for your primary target entity indicates that Google is likely treating the entity as the document’s main subject. Scores between 0.10 and 0.50 are acceptable for supporting entities. Any target entity scoring below 0.10 should be treated as a content optimization priority, as it suggests the document is not clearly communicating that entity as a central topic.
Is the Google NLP API the same tool Google uses to rank content?
The Google Cloud Natural Language API is a publicly available version of Google’s NLP infrastructure, but it is not identical to the internal systems used in ranking. It provides useful directional data about how Google parses entities and their salience in a document. Treat the API output as a proxy signal, not a direct window into the ranking algorithm.
How is entity salience different from TF-IDF?
TF-IDF measures how frequently a term appears in a document relative to how frequently it appears across a corpus. Entity salience measures the semantic centrality of a named entity to the document’s overall meaning, accounting for position, context, and entity type, not just term frequency. A term can have high TF-IDF and low entity salience if it appears frequently but in a peripheral context. Salience is a more direct measure of how Google understands what a page is about.
Can you run entity salience analysis on a competitor’s page?
Yes. The API call accepts any text content, so you can fetch a competitor’s page using WebFetch inside Claude Code, strip the HTML, and run the same analysis. This tells you which entities their top-ranking pages prioritize and at what salience levels, which is useful data for gap analysis. The co-occurrence analysis workflow in this series builds on this competitor entity data.
What happens if my target entity returns no Wikipedia metadata?
An entity with no Wikipedia metadata in the API response means Google cannot resolve it to a specific Knowledge Graph entry with confidence. This is an entity disambiguation signal, not necessarily a salience problem. Fixes include adding sameAs schema markup pointing to Wikidata or Wikipedia entries, building citations on authoritative sites that describe your entity clearly, and creating or improving a Wikipedia page if the entity meets notability standards.
How often should you run an entity salience audit?
Monthly is a reasonable baseline for active sites publishing new content regularly. Run an audit after any significant content update to a flagged page to confirm the salience score improved. For client sites, include entity salience scores in monthly reporting alongside GSC performance data to connect content structure changes to ranking outcomes over time.
Does entity salience apply to all page types or just blog posts?
Entity salience applies to any page Google indexes, including service pages, location pages, product pages, and homepage content. Service pages and location pages often have the most to gain from salience optimization because they carry direct commercial ranking intent. A service page where the primary service entity scores below 0.10 is a common finding in technical SEO audits and one of the faster wins to address once the workflow is in place.