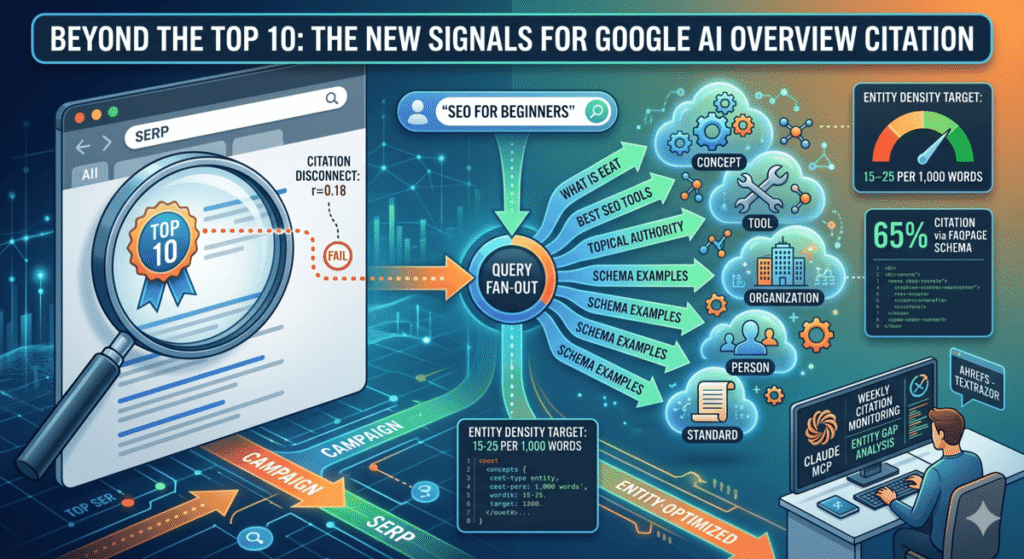
Google AI Overviews do not pull citations from the top-ranked pages the way most SEOs assume. An Ahrefs study of 300,000 keywords and 4 million AI Overview URLs found that only 38% of cited pages rank in the top 10 for the same query. As recently as late 2024, that number was 76%. The shift means traditional ranking signals are increasingly a weak predictor of AI Overview citation, and something else is doing more of the work. That something is entity density — specifically, how many distinct, recognized entities your page contains and how well those entities connect to the semantic neighborhood Google expects around your topic. This post covers the specific entity signals that correlate with AI Overview citation, the five entity types that matter most, and a Claude workflow that audits your pages, scores your entity gap, and monitors your citation status weekly without any manual reporting.
Why Rankings No Longer Predict AI Overview Citations
The citation-ranking disconnect accelerated sharply in January 2026 when Google upgraded AI Overviews to Gemini 3. That upgrade replaced approximately 42% of previously cited domains and added 32% more source URLs per AI Overview response. The mechanism behind both changes is query fan-out.
When a user submits a query, Google’s AI decomposes it into multiple related sub-queries and pulls citation sources across all of those sub-query SERPs, not just the original query’s top results. A page that ranks #12 for the primary query but appears in multiple sub-query results can end up cited more reliably than a page that ranks #1 but only matches the surface-level query.
The citation distribution data from Ahrefs confirms this: 37.1% of cited pages rank in positions 1-10, 26.2% rank positions 11-100, and 36.7% rank outside the top 100 entirely. That last number means roughly one in three cited pages has essentially no traditional organic visibility for the same query. Domain authority shows a correlation of only r=0.18 with AI Overview citation, down from 0.23 in 2024.
One counterintuitive finding rounds out the picture: content length has a 0.04 correlation coefficient with AI Overview citations, and 53% of cited pages are under 1,000 words. Writing longer content is not the answer. Having the right entities is.
What Actually Drives AI Overview Citation?
Two signals stand out in the research as genuinely predictive: entity density and structured data.
Entity density. Research published in April 2026 identified a specific threshold: pages with 15 or more distinct entities per 1,000 words show 4.8 times higher AI Overview selection probability than pages below that threshold. The optimal range is 15 to 25 entities per 1,000 words. Above 30, the signal starts to look like stuffing and the benefit drops off.
What counts as a distinct entity matters here. The research identifies five categories:
- Concept entities: Named frameworks and abstract ideas directly relevant to the topic (query fan-out, E-E-A-T, topical authority, passage indexing)
- Tool and platform entities: Named software, platforms, and services (TextRazor, Ahrefs, Google Search Console, Screaming Frog)
- Organization entities: Companies and institutions with Knowledge Graph presence (Google, Anthropic, Schema.org, Wikipedia)
- Person entities: Named researchers, practitioners, and thought leaders cited in the field
- Standard and specification entities: Named protocols and frameworks (JSON-LD, FAQPage schema, Core Web Vitals, structured data)
Most SEO content is heavy on concept entities and almost completely missing tool, person, and standard entities. That imbalance lowers the total entity count and reduces the page’s coverage of the semantic neighborhood Google expects around the topic.
Structured data. A SE Ranking analysis found that 65% of pages cited in AI Overviews include structured data markup, compared to roughly 35-40% of high-ranking pages broadly. A separate analysis attributed a 73% selection boost to schema implementation. The schema types with the clearest citation relevance are FAQPage, HowTo, Article, and Organization. FAQPage schema is particularly useful because Google’s query fan-out generates sub-queries that look exactly like FAQ questions, and FAQPage schema gives the AI a pre-structured answer to pull.
These two signals compound. A page with high entity density and FAQPage schema is serving Google’s AI both the contextual depth it needs and a structured format it can extract from cleanly.
How to Audit Your Entity Gap with Claude and TextRazor
The audit workflow has five steps. All of it runs in Claude Code in a single session. I store the target queries and baseline results in a CLAUDE.md file so the monitoring step has a baseline to compare against each week.
Step 1: Identify which queries trigger AI Overviews and pull the cited sources.
Ask Claude to use the Ahrefs MCP to pull SERP data for your target queries. The serp-overview tool returns which queries have AI Overviews active and lists the source URLs being cited.
Use the Ahrefs MCP serp-overview tool for each of these queries:
[list of 5-10 target keywords]
For each query, return:
- Whether an AI Overview is present
- The URLs being cited in the AI Overview
- The position of each cited URL in organic results
Save the cited URLs to CLAUDE.md as the baseline for weekly monitoring.
This gives you the exact pages Google is selecting to answer your target queries. Those are your benchmarks.
Step 2: Build entity profiles for the cited pages.
For each cited URL, ask Claude to fetch the page and run it through TextRazor to extract entities. This is the same TextRazor pipeline I covered in the entity co-occurrence audit post. The key addition here is categorizing each entity by type and counting total entities per 1,000 words.
For each cited URL in CLAUDE.md:
1. Fetch the page with WebFetch and extract plain text
2. Call TextRazor (key in settings.json) with extractors=entities
3. Filter to confidenceScore >= 1.5
4. Categorize each entity: Concept / Tool / Organization / Person / Standard
5. Count word count and calculate entities per 1,000 words
6. Return a profile: total entity count, density score, breakdown by category, schema types present
The schema type check is a simple one — look for JSON-LD blocks in the HTML and note which @type values are present. Claude can do this from the raw WebFetch output before extracting plain text.
Step 3: Run the same pipeline on your page.
Identical process on the page you want to get cited. You now have two comparable data sets: cited pages and your page. The gap report writes itself.
Step 4: Generate the gap analysis.
Compare my page's entity profile against the cited page profiles:
1. Entity density: my score vs. average cited page score vs. 15-entity threshold
2. Missing entity categories: which of the five types am I low on?
3. Missing specific entities: which named entities appear in 2+ cited pages but not mine?
4. Schema gap: which schema types do cited pages use that I am missing?
Return a prioritized gap list, highest-impact first.
The output is a ranked list of exactly what to add to close the gap. The most common finding I see running this across client pages: very thin tool and person entity coverage. A post about technical SEO that mentions no tools by name and cites no researchers is scoring near zero on two of the five entity categories. Adding four or five specific tool mentions with one sentence of context each can push a page across the 15-entity threshold without adding significant word count.
Step 5: Add the missing entities as natural content additions.
Ask Claude to draft the specific additions based on the gap list. The constraint is that each entity must be introduced with enough context to be genuinely useful, not just named and dropped.
For each priority gap entity, draft 1-2 sentences that introduce it naturally
within the context of [topic]. The entity should be named, given a one-line
description of what it is or does, and connected to the main argument of the page.
Do not add filler. Each addition should be something a reader would find
specifically useful.
This is the step where CLAUDE.md earns its keep. Because Claude has your brand voice, your audience definition, and your content standards stored in the project file, the draft additions match the page’s existing tone without needing edits. The same workflow I use for client page improvements is available to you in your own projects. See my posts on building entity authority with Claude and scoring entity salience for the underlying pipeline this builds on.
What to Prioritize When Your Entity Density Is Below 15
If your entity density is below 15 per 1,000 words, the fastest path to closing the gap is usually one of three additions rather than a full page rewrite.
- Add a tools section. A paragraph or sidebar listing the specific tools relevant to your topic, with one sentence on what each does and why it matters to the subject, typically adds four to eight tool entities in 150 words. TextRazor, Ahrefs, Google Search Console, Screaming Frog, and Wikidata SPARQL are all recognized Knowledge Graph entities. Naming them in context counts.
- Cite researchers and practitioners by name. Ahrefs, BrightEdge, Seer Interactive, and SE Ranking all produce research on AI Overviews. Naming the organization and attributing a specific finding to them adds organization entities and also signals to Google that the content is connected to recognized sources in the field. Attribution is not just an ethical requirement. It is an entity signal.
- Add a definitions section or expand your FAQ. Defining four or five core concepts from the topic — with their proper names as used in Google’s Knowledge Graph — adds concept entities in a format that is easy for the AI to extract. This is also where FAQPage schema has the highest return. Mark up your FAQ section with FAQPage schema and you have addressed both the entity gap and the structured data gap in one block of content.
How to Monitor AI Overview Citations with /loop
Running the audit once is useful. Running it weekly is where the compounding happens. After the initial audit, I set up a /loop command that checks AI Overview appearance for the target query set on a weekly cadence.
The CLAUDE.md at the project root stores the baseline: which queries trigger AI Overviews, which URLs are cited, and your page’s entity density score at the time of the initial audit. Each week, Claude re-runs the serp-overview check via Ahrefs MCP and compares the current cited URLs against the baseline.
Check AI Overview status for all target queries in CLAUDE.md.
For each query:
1. Is an AI Overview present? (yes/no — note any queries where it disappeared)
2. Is my page ([URL]) now cited? If yes, mark it and note the query.
3. Have any previously cited pages dropped out? List them.
4. Have any new pages appeared that were not in the baseline? Add them to the benchmark list.
Return a delta report showing changes since last check.
The delta report answers the only question that matters: is the entity work producing citation appearances? If a page gets cited for a query it was not cited for last week, the report flags it. If the citations are stable or declining, that is a signal to look at what changed, either on your page or in the competitive set. This monitoring loop is what most practitioners skip, and it is the step that turns a one-time audit into an ongoing advantage. The underlying data on topical authority and answer engine optimization gives this loop additional context if you are building a full AEO strategy alongside the entity work.
Frequently Asked Questions
How many entities does a page need to appear in Google AI Overviews?
Research published in April 2026 identifies 15 distinct entities per 1,000 words as the threshold where AI Overview selection probability increases 4.8 times. The optimal range is 15 to 25 entities per 1,000 words. Beyond 30, the benefit drops off and may look like over-optimization.
Does a page need to rank in the top 10 to appear in Google AI Overviews?
No. An Ahrefs study of 863,000 keywords found that only 38% of AI Overview-cited pages rank in the top 10 for the same query. Approximately 36.7% of cited pages rank outside the top 100. The citation selection operates on different signals than organic ranking, particularly query fan-out and entity density.
What schema types help with AI Overview citation?
FAQPage, HowTo, Article, and Organization schema types appear most frequently among AI Overview-cited pages. FAQPage is particularly useful because Google’s query fan-out generates sub-queries that match FAQ-style questions, and FAQPage schema provides pre-structured answers the AI can extract directly. Research finds 65% of cited pages include structured data, compared to roughly 35-40% of high-ranking pages broadly.
What are the five entity types that matter for AI Overview optimization?
Concept entities (named frameworks and abstract ideas), tool and platform entities (named software and services), organization entities (companies and institutions with Knowledge Graph presence), person entities (named researchers and practitioners), and standard and specification entities (protocols and technical frameworks like JSON-LD and FAQPage schema). Most content is heavy on concepts and thin on tools, persons, and standards.
How does query fan-out affect which pages get cited?
When Google generates an AI Overview, it decomposes the original query into multiple related sub-queries and pulls citation sources across all of those sub-query SERPs. A page that appears in results for multiple sub-queries gets cited even if it does not rank highly for the original query. This is why pages ranking outside the top 100 for a query can still be cited in the AI Overview for that same query.
How do I use Claude to monitor my AI Overview citation status?
Store your target queries and baseline cited URLs in a CLAUDE.md file at your project root. Use the Ahrefs MCP’s serp-overview tool inside a /loop command to check citation status weekly. Claude compares the current cited URLs against the baseline and returns a delta report showing new citations, dropped citations, and new competitive entries. This turns the audit from a one-time check into a weekly feedback loop.