Before Google can cite your page in AI Overviews, surface your Knowledge Panel, or give you entity-level authority on a topic, it has to be certain about something more basic: that it knows which entity you are. Not just that a “Michael Cortez” exists somewhere on the internet – but that the Michael Cortez writing about semantic SEO on this site, the Michael Cortez on LinkedIn, and the Michael Cortez in a Wikidata entry are the same person. That process of resolving ambiguity is entity disambiguation, and getting it wrong – or never addressing it – quietly caps everything else you build. This post covers how Google’s disambiguation system works, the framework Jason Barnard of Kalicube developed to systematically resolve it, why Wikidata is the most underused lever in this process, and a Claude workflow that audits your current entity status, identifies corroboration gaps, and drafts the Wikidata entry and schema markup needed to close them.
What Does Entity Disambiguation Actually Mean?
Google’s Knowledge Graph stores entities — not strings of text. When someone searches “Danny Goodwin,” Google has to decide which Danny Goodwin the query refers to: the Search Engine Land editorial director or the Hall of Fame baseball player. For over a decade, it chose wrong. Every article Danny Goodwin (the SEO journalist) published was attributed in Google’s system to the baseball player. His Knowledge Panel didn’t exist. His E-E-A-T signals didn’t accumulate the way they should have because Google couldn’t reliably attach his content to the correct entity node.
The root cause was probabilistic. Google’s Knowledge Graph is built on weighted evidence from public data. A decade of baseball statistics, Wikipedia entries, and sports coverage created a deeply reinforced association between “Danny Goodwin” and the baseball player. The system fed itself, compounding the error until correction required systematically re-educating the algorithm rather than simply adding new signals.
Most disambiguation problems are less severe than this, but the underlying mechanism is the same. If you share a name with someone more prominent, if your brand name is also a common word, or if your entity appears under multiple slightly different name forms across the web, Google’s confidence in your entity identity drops — and lower confidence means weaker Knowledge Panel, weaker E-E-A-T attribution, and lower AI Overview citation probability. The signals from entity density research and co-occurrence analysis only work if Google knows which entity they belong to.
The Three-Entity Problem Google Has With Your Brand
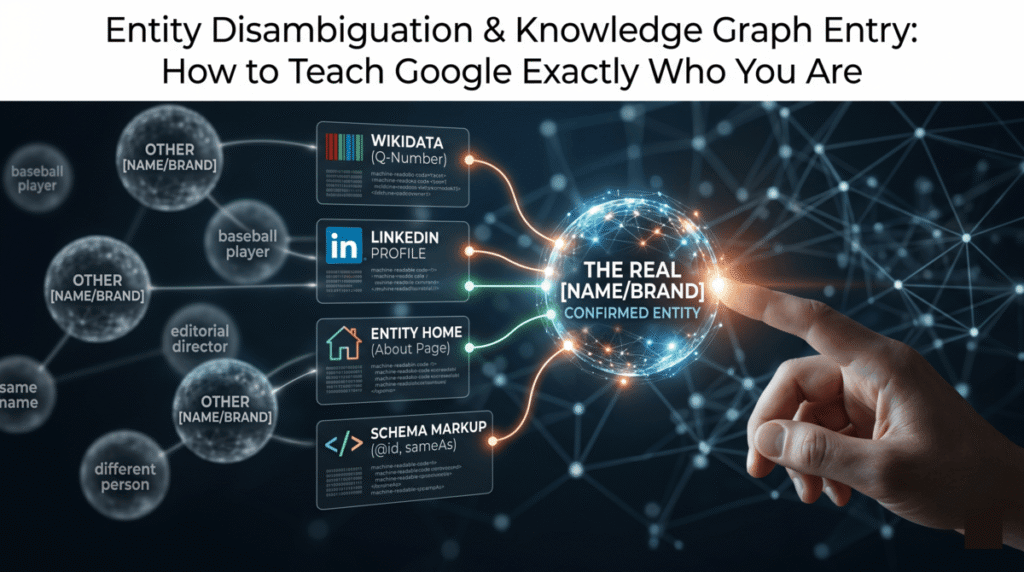
Here is a problem most practitioners don’t realize they have: Google may be treating you, your website, and your brand as three separate entities rather than one.
In Google’s model, a person entity (Michael Cortez), an organization entity (Webfor), and a website entity (michaelpatrickcortez.com) are distinct nodes in the Knowledge Graph. They have relationships — the person works for the organization, the website belongs to the person — but they start as separate entries that need explicit linking before Google treats them as facets of the same thing.
The @id property in schema markup handles the internal linking. A stable, consistent @id value in your JSON-LD tells Google’s crawler: this page is an authoritative description of a specific entity, identified by this URI. When Google sees the same @id across your homepage, About page, and author bios, it can merge those signals into a single entity node rather than treating each page as a separate ambiguous reference.
The sameAs property handles the external linking. Where @id connects pages within your site, sameAs connects your entity to the same entity as defined in external authoritative sources — your Wikidata Q-number, your LinkedIn URL, your Wikipedia article if you have one. Three to five high-authority sameAs references do more disambiguation work than twenty references to low-authority directories, because Google cross-checks these to validate entity claims rather than simply counting them.
Jason Barnard’s Entity Home: City Hall for Your Digital Identity
Jason Barnard, known in the industry as The Brand SERP Guy and founder of Kalicube, coined the concept of the Entity Home in 2019. His definition is precise: the Entity Home is the single URL that Google treats as the definitive, authoritative source of facts about your entity. Not your homepage necessarily. Not your LinkedIn. The specific page — usually your About page or a dedicated bio page — where you state the complete, accurate, machine-readable description of who you are and what you do.
Barnard’s analogy is exact: “your Entity Home Website would be city hall — the official, authoritative place every map, media outlet, and AI system checks.” When Google encounters your name on 500 different sites, it needs one reference point to reconcile which entity all those mentions refer to. The Entity Home is that reference point.
The Entity Home operates across what Barnard calls the Understandability-Credibility-Deliverability framework. Understandability: it signals to search engines that this is the entity’s official voice. Credibility: it hosts verifiable information (credentials, affiliations, publication history) that can be cross-checked against third-party sources. Deliverability: it provides machine-readable, structured content accessible to AI systems for accurate representation.
What belongs on an Entity Home page:
- A consistent name in exactly the form you want Google to recognize (no variations)
- A clear, declarative description using a semantic triple structure: “[Name] is [role] at [organization]”
- Affiliations, credentials, and publication outlets with named links to each
- Person or Organization schema with
@idset to a stable URI (e.g.,https://yoursite.com/#person) sameAspointing to your Wikidata Q-number, LinkedIn, Wikipedia (if applicable), and any other authoritative profiles- Links out to all external profiles (not just listed in schema — actual anchor links on the page)
The critical warning Barnard issues: getting information wrong at the Entity Home level is very difficult to correct. If incorrect facts enter the Knowledge Graph, correction requires removing and rebuilding the entity understanding, which can double the timeline. Accuracy before submission matters more than speed.
Understanding vs. Confidence: Two Distinct Stages Google Has With Your Entity
One of Barnard’s most useful distinctions is separating Google’s understanding of an entity from its confidence in that understanding. These are not the same thing, and treating them as one is why many practitioners stall partway through the process.
Understanding gets an entity into what Google internally calls the Knowledge Vault — the broader repository of entity knowledge the Knowledge Graph draws from. At the understanding stage, Google has enough signal to know you exist as a distinct entity, but not enough to surface a stable Knowledge Panel or make confident attribution decisions.
Confidence is what keeps the entity stable. This is built through corroboration — not just having one source that says who you are, but having multiple independent, authoritative sources that all state the same facts in a consistent form. When Google encounters your name on a podcast profile, a conference speaker page, an industry directory, and a Wikidata entry, and all of those sources say the same role, affiliation, and description, confidence rises. Inconsistency — different job titles, different name forms, different affiliations across sources — actively suppresses confidence even when the entity is correctly identified.
The Kalicube Process addresses both stages in sequence:
- Build and optimize the Entity Home (creates the authoritative reference point)
- Secure corroboration from multiple independent, authoritative sources (builds understanding)
- Create an infinite self-confirming loop — each corroboration source links back to the Entity Home, which links out to the corroboration sources, which all state the same facts (builds confidence and maintains stability)
The Danny Goodwin disambiguation followed this sequence exactly. Step one was building a dedicated Entity Home at dannygoodwin.info with a clear semantic triple in the biography. Step two was updating all controlled digital properties with consistent descriptions. Step three was creating backlinks from those properties back to the Entity Home. The timeline: month four brought a unique Knowledge Graph identifier, month six produced Knowledge Panel cards, month nine stabilized the description, and month twelve showed accurate “People also search for” results featuring Barry Schwartz instead of an unrelated psychologist.
Why Wikidata Is the Most Underused Tool in This Process
Most SEO practitioners know Wikidata exists. Far fewer have actually created or claimed their entity’s entry there, even though Wikidata has a direct pipeline into Google’s Knowledge Graph and does not require Wikipedia-level notability to create an entry. Any verifiable entity — a person with a publication record, a business with a registered address, a podcast with a verifiable distribution history — can have a Wikidata entry if the facts can be cited to third-party references.
The 2024 Google leak revealed something counterintuitive about reference sources: Wikipedia and Wikidata together account for only 12.15% of reference sources for the 7.7 million entities in Google’s system. Author pages and industry sites carry more weight in aggregate than most practitioners assume. But Wikidata is different from those sources in one critical way — it is machine-readable and structured. When Google reads a Wikidata entry, it does not have to interpret natural language or infer relationships. The entity type, the properties, and the relationships are all explicit. That clarity has disambiguation value that unstructured text mentions do not.
The key Wikidata properties for a person entity:
- P31 (instance of): human (Q5) — this tells Wikidata and Google that this entry is a person
- P106 (occupation): your primary role as it exists in Wikidata (e.g., search engine optimization consultant)
- P21 (sex or gender): male (Q6581097) or female (Q6581072)
- P27 (country of citizenship): your country
- P856 (official website): your Entity Home URL — this is the Wikidata-to-Entity-Home link
- P18 (image): a professional photo hosted on Wikimedia Commons
- P108 (employer): links to your organization’s Wikidata entry if it has one
- P2002 / P2003 / P4033 (social profiles): Twitter, Instagram, Mastodon handles
- P968 (email) or contact information links as applicable
For an organization entity, the core properties shift:
- P31: organization (Q43229) or business (Q4830453)
- P571 (inception): founding date
- P159 (headquarters location): city and country
- P856 (official website): your Entity Home URL
- P452 (industry): the industry classification
Every statement in Wikidata requires a reference — a citation to a verifiable source. This is not optional. Statements without references are flagged as unsourced and carry less weight in disambiguation. Use your Entity Home page, LinkedIn, official registrations, and press coverage as references for each statement.
How to Audit and Build Your Entity Presence with Claude
The audit covers four areas: your current Wikidata status, your Entity Home completeness, your corroboration consistency, and your schema markup. Claude runs each with a different tool.
Step 1: Check your Wikidata entity status with SPARQL.
The Wikidata SPARQL endpoint is already available in the Entity Clarity tool. In a Claude session, ask it to run a SPARQL query to check whether your entity exists and what properties are currently filled in:
Run a Wikidata SPARQL query to check whether [your name] or [your organization]
has an existing Wikidata entry. If found, return:
- The Q-number
- All currently filled properties (P-numbers) and their values
- Properties present in well-formed entries for similar entities that are missing from this one
If no entry exists, confirm and proceed to Step 2.
If an entry exists but is incomplete, the gap list from this query tells you exactly which properties to add. If no entry exists, Claude can draft the full entry based on your CLAUDE.md context in the next step.
Step 2: Draft your Wikidata entry.
With your CLAUDE.md loaded (which contains your bio, affiliations, publication history, and professional context), ask Claude to draft a complete Wikidata entry in the format required for manual submission:
Using the context in CLAUDE.md, draft a complete Wikidata entry for [name/organization].
Include:
- P31 (instance of) with correct Q-number
- All applicable properties from the standard list for this entity type
- A reference source for each statement (use Entity Home URL, LinkedIn, or press coverage)
- English description in the format "[role] from [location]" (under 250 characters)
- Aliases to cover common name variations
Format as a structured list of property → value → reference triples,
ready for manual entry at wikidata.org.
The description field is worth extra attention. This is what appears under your name in disambiguated search results and in some Knowledge Panel contexts. It should state your primary role and differentiate you from anyone who shares your name. “Digital marketing consultant from Portland, Oregon” is more useful for disambiguation than “SEO expert and content strategist.”
Step 3: Audit your Entity Home for completeness.
Ask Claude to fetch your About page and evaluate it against the Entity Home checklist:
Fetch [Entity Home URL] and evaluate it as a Barnard-style Entity Home.
Check for:
1. Consistent name form (matches Wikidata label and LinkedIn exactly?)
2. Semantic triple in the bio: [Name] is [role] at [organization] — present and clear?
3. Named affiliations with hyperlinks to each
4. Person or Organization schema present?
5. @id set to a stable URI?
6. sameAs array — which authoritative sources are included, which are missing?
7. Outbound links to all controlled profiles (LinkedIn, Wikidata, social, etc.)?
8. Any name variations on the page that could create ambiguity?
Return a pass/fail for each item and a prioritized fix list.
Step 4: Run a corroboration consistency audit with the Ahrefs Brand Radar.
Corroboration fails when external sources describe you inconsistently. The Ahrefs Brand Radar MCP can pull mentions of your brand or name across the web. Ask Claude to use it to identify the top-20 external sources mentioning your entity and then check each for description consistency:
Use the Ahrefs Brand Radar MCP to pull the top 20 external sources mentioning [name/brand].
For each source, check:
- What name form do they use? Does it match the Entity Home exactly?
- What role or description do they use? Does it match the Wikidata description?
- Do they link back to the Entity Home?
- Is the information current?
Flag any source using a different name form, outdated title, or missing Entity Home link.
Return a corroboration consistency score and a fix list by source.
Corroboration sources that use different title formats, outdated affiliations, or no link back to the Entity Home are actively suppressing your confidence score. Updating each of those sources — even just getting them to link to your Entity Home — directly improves Google’s ability to maintain a stable entity understanding.
Step 5: Generate the complete schema markup.
With the Wikidata Q-number confirmed and the corroboration sources identified, ask Claude to generate the final JSON-LD for your Entity Home page:
Generate complete JSON-LD schema markup for [Entity Home URL].
Entity type: Person (or Organization)
Include:
- @context: https://schema.org
- @type: Person
- @id: [stable URI, e.g., https://yoursite.com/#person]
- name: [exact match to Wikidata label]
- url: [Entity Home URL]
- jobTitle: [role]
- affiliation: [linked organization with its own @id]
- sameAs array: [Wikidata URL, LinkedIn URL, Wikipedia URL if applicable, Google Business Profile if org]
- description: [Wikidata description text]
Use the @id value consistently wherever this entity is referenced in schema
across the site (author bios, article schema, etc.).
The @id value you set here should be used consistently in every piece of Article schema on the site, in the author field. This connects your authorship attribution to the correctly disambiguated entity node — which is exactly what the Danny Goodwin case identified as the missing signal. Google was able to understand the entity before it was able to correctly attribute the articles, and the isAuthor signal was the last thing to resolve.
Step 6: Set up /loop monitoring for Knowledge Panel changes.
Knowledge Panel changes happen in “slow, iterative waves” according to the Danny Goodwin case documentation — updates propagate across Google’s Knowledge Graph, web index, and LLM systems at different speeds. A weekly /loop check tells you when changes land and whether they reflect what you expect:
Check the Google Knowledge Panel status for [entity name].
Search [name + location/role identifier] and report:
- Does a Knowledge Panel appear?
- What name, description, and image does it show?
- What "People also search for" entities appear?
- Any inconsistencies with the Entity Home information?
Compare against the baseline in CLAUDE.md and flag any changes.
The “People also search for” section is one of the most revealing indicators of disambiguation progress. When it shows thematically related peers (other SEO practitioners, for example) rather than random unrelated entities, it confirms that Google has correctly placed your entity within the right semantic neighborhood.
What to Expect on the Timeline
Barnard’s process takes three months to two years, and that range is not imprecision — it reflects the genuine variability in how quickly Google updates entity confidence based on how much conflicting prior data exists. Entities starting from zero ambiguity and clean corroboration move faster. Entities correcting long-standing confusion move slower.
The Danny Goodwin case – correcting a decade of entrenched wrong data – took twelve months. A new entity with no conflicting associations and a well-built corroboration loop can trigger a Knowledge Panel in four to six weeks.
The sequencing matters more than the speed. Entity Home first. Wikidata entry with references second. Schema with consistent @id and sameAs third. Corroboration source cleanup fourth. Monitor weekly. Do not add incorrect information to speed up the process – the remediation cost is double the initial build cost.
Frequently Asked Questions
What is entity disambiguation in SEO?
Entity disambiguation is the process of teaching Google’s Knowledge Graph to correctly and confidently identify which real-world entity a name or brand refers to, distinct from any other entities that share similar identifying information. When disambiguation fails, Google may conflate two people with the same name, misattribute content, or be unable to build a stable Knowledge Panel.
What is an Entity Home and why does it matter?
An Entity Home, a concept developed by Jason Barnard of Kalicube, is the single page on your website that serves as the authoritative source of facts about your entity. It is the URL Google reconciles all external mentions back to. It needs consistent name form, a declarative bio in semantic triple structure, named affiliations with links, and complete schema markup with @id and sameAs. Without a clear Entity Home, Google has no anchor point to resolve ambiguity.
Do I need a Wikipedia article to appear in Google’s Knowledge Graph?
No. Wikidata entries do not require Wikipedia-level notability. Any entity whose facts can be cited to verifiable third-party sources can have a Wikidata entry. Wikidata is structured and machine-readable, which gives it disambiguation value that exceeds many unstructured text mentions in aggregate. A well-built Wikidata entry with properly cited statements is often more effective than a short Wikipedia article for Knowledge Graph purposes.
What is the difference between @id and sameAs in schema markup?
The @id property creates a stable internal identifier for your entity that Google’s crawler can use to merge signals across multiple pages on your site. The sameAs property connects your entity to the same entity as described in external authoritative sources — your Wikidata Q-number, your LinkedIn URL, your Wikipedia article. @id handles internal disambiguation; sameAs handles external corroboration.
How long does it take to get a Google Knowledge Panel after building an Entity Home?
Jason Barnard’s Kalicube Process documentation cites three months to two years. The Danny Goodwin case — resolving a decade of conflation with a baseball player — took twelve months from Entity Home creation to stable Knowledge Panel with accurate entity associations. New entities with no conflicting prior data and strong corroboration can see Knowledge Panel appearance in four to six weeks. Accuracy of inputs matters more than speed of submission.
How does entity disambiguation connect to AI Overview citations?
AI Overview citation probability correlates with entity density and entity recognition. Pages written by authors with correctly disambiguated entity nodes carry stronger E-E-A-T attribution signals. The isAuthor signal connects your content to your entity in Google’s system — but that connection only works if Google is confident about which entity you are. Entity disambiguation is the prerequisite step for all downstream entity-based SEO, including the AI Overview optimization workflow covered in the previous post in this series.
What are the most important Wikidata properties for a person entity in SEO?
The highest-priority properties are P31 (instance of: human), P106 (occupation), P856 (official website, pointing to your Entity Home), P27 (country of citizenship), and P18 (image). Each statement requires a reference citation to a verifiable source. The description field (under 250 characters, format: “role from location”) is particularly important for disambiguation because it is what Google uses to differentiate entities with similar names.