GEO (Generative Engine Optimization) and SEO are not the same discipline with a new name. They optimize for different retrieval systems, measure success differently, and require different content decisions. SEO earns rankings and clicks. GEO earns citations inside AI-generated answers, and the overlap between those two outcomes has collapsed from roughly 75% in mid-2025 to somewhere between 17% and 38% today.
If you rank first on Google, you are no longer automatically getting cited in AI Overviews, ChatGPT, or Perplexity. And if you get cited in those platforms, you are no longer automatically ranking. The two systems have diverged, and tactics that win in one do not reliably transfer to the other.
This post covers what that divergence means in practice, including what the current crop of GEO guides gets wrong about schema, markdown, and llms.txt, and what two emerging standards (EntityMap and agentic RAG) tell us about where things are heading in the second half of 2026.
The Traffic Data Worth Taking Seriously
Some numbers worth calibrating against before getting into strategy.
Zero-click searches on Google climbed from 56% to 64.82% after AI Overviews rolled out at scale. For queries that trigger an AI Overview specifically, that rate exceeds 80%. Organic click-through rates for informational queries are down 61% since the rollout. For every 100 clicks a number-one ranking used to generate, sites now earn roughly 35.
On the AI side: AI search traffic grew 527% in the 12 months through early 2026. Gartner projects 25% of organic search traffic will shift to AI chatbots and voice assistants by the end of 2026. A 2026 study of 34,234 AI responses found citation rates vary by 46x across platforms. Perplexity cites brands 13.05% of the time. ChatGPT does so at just 0.59%.
Two visibility systems now run in parallel with different audiences, different signals, and different conversion profiles. Running only one of them is a strategic choice with measurable costs.
Where SEO Still Wins
The “SEO is dead” frame fails because it treats all search intent as identical.
Google still processes 8.5 billion queries per day. Transactional queries like “buy running shoes near me,” “best price on X,” or “hire a plumber Vancouver WA” still resolve with clicks. Local intent still routes through Maps and the local pack. Navigational queries go directly to destinations. E-commerce impact from AI Overviews has been measured at roughly 4%, effectively minimal.
The queries where SEO has eroded sharpest are informational: “what are the best running shoes for plantar fasciitis,” “how does a HELOC work,” “what is topical authority in SEO.” These are the queries where AI systems now synthesize a direct answer rather than serving a results page. For those queries, being cited in the AI answer is the new first position.
If your audience searches with commercial or transactional intent, SEO remains the primary channel. If your audience is researching, comparing, or learning, GEO is where the visibility is.
What GEO Actually Is
Generative Engine Optimization is the practice of structuring content so AI retrieval systems select it as a source when generating answers. The formal research comes from a 2024 paper by Aggarwal et al. from Princeton, Georgia Tech, the Allen Institute for AI, and IIT Delhi, presented at KDD 2024. The study tested nine optimization tactics across 10,000 queries in 25 domains, measuring visibility through a Position-Adjusted Word Count metric that weights how much of your content appears in AI responses and where it appears.
Five tactics produced measurable lifts:
- Statistics addition: +41% visibility
- Citing external sources: +30% overall, up to +115% for lower-ranked content
- Quotation addition: +28%
- Fluency optimization: +28%
- Authoritative voice: smaller but measurable lift
Combining statistics addition with fluency optimization produced the largest combined effect in the study.
What most guides written by agencies selling GEO services will not tell you is Mike King’s reframe. King, founder of iPullRank and author of the AI Search Manual, argues that collapsing GEO into “modern SEO” serves platform interests over practitioner ones. His position: GEO requires distinct competencies that traditional SEO training does not cover, including information retrieval theory, vector distance measurement, RAG pipeline analysis, and passage-level content engineering. Google’s own published guidance states that systems “understand synonyms and general meanings” without requiring specific writing approaches. King points out this directly contradicts Google’s own MUVERA research and passage indexing patents, which show that specificity, entity salience, and semantic coherence produce measurably different vector distances. His read: Google frames GEO as “just modern SEO” because it keeps practitioners optimizing for one platform.
The Citation Divergence Is Bigger Than Most People Realize
The overlap between pages that rank in Google’s top 10 and pages that get cited by AI systems fell from approximately 75% in mid-2025 to between 17% and 38% by early 2026, according to multiple independent analyses including data from BrightEdge and SE Ranking. Fewer than 10% of sources cited by ChatGPT, Gemini, and Copilot rank in Google’s top 10 for the same query. 47% of AI Overview citations now come from pages ranking below position five. Domain Authority correlation with AI citations dropped to r=0.18.
The signals that predict AI citation look different from the ones that predict rankings. An Ahrefs analysis of 75,000 brands and 76 million AI Overviews (May 2025, by Louise Linehan and Xibeijia Guan) found brand mention signals correlate with AI Overview citation at 0.664 — more than three times the predictive power of raw backlinks at 0.218. Promotional tone actively hurts citation rates. Content that reads like a pitch is deprioritized by AI retrieval systems across platforms. Original research has 5.2x the citation probability of synthesized content, per the Princeton GEO study.
44.2% of all AI citations come from the first 30% of a piece of content, overwhelmingly from introductions and opening sections. Direct answers placed in the first 40-60 words improve citation likelihood by up to 115% for lower-ranked content. Where the answer lives on the page matters more for GEO than it does for SEO.
The Three Platforms Do Not Work the Same Way
Every guide currently ranking for “GEO vs. SEO” treats ChatGPT, Perplexity, and Google AI Overviews as interchangeable. They are not. The citation mechanisms are architecturally different, and optimizing for one does not guarantee performance in the others.
Google AI Overviews
AI Overviews pull from a broader index than the organic top 10, which is already established by the citation divergence data above. The optimal passage length for extractability falls between 134-167 words. 96% of AI Overview citations come from sources with strong E-E-A-T signals. The top cited domains include YouTube at 23% of citations, Wikipedia at 18%, and Google.com at 16%. The top 15 domains capture roughly 68% of all AI citation share, according to the AI Platform Citation Source Index 2026.
Google confirmed in its own documentation that there is “no special schema.org structured data you need to add” for AI Overviews or AI Mode. What that actually means for schema strategy is covered below.
ChatGPT
ChatGPT uses a hybrid of training data and selective Bing web retrieval. It cites brands just 0.59% of the time across responses, per a 2026 study of 34,234 AI responses. The site: operator, which used to surface what ChatGPT knew about a domain, collapsed from a 40.5% match rate to 12.6% following GPT-5.x model updates, as tracked in the Post 35 research on how to rank in ChatGPT. Bing indexation is the primary lever for web-retrieved citations. Earned media is cited 5x more than brand-owned content.
LLM visitors from ChatGPT convert at 15.9%, compared to a 1.76% organic search conversion average. The audience arriving from a ChatGPT citation has already been pre-qualified by the AI’s answer.
Perplexity
Perplexity runs a real-time web search for every query with no training data dependency. A single high-authority earned mention can show up in Perplexity citations within days, making it the fastest platform to influence. It cites brands at 13.05%, which is 22x the rate of ChatGPT. AI-referred visitors convert at roughly 11x the rate of traditional organic search traffic: 1.66% versus 0.15%, per the Digital Bloom Gen AI Website Traffic Share Report (February 2026). Perplexity drives a disproportionate share of that high-converting AI traffic, with a 10.5% conversion rate tracked in the same report.
To build AI citation presence quickly, Perplexity is the most responsive platform. To build it durably across ChatGPT, the game is earned media and Bing indexation over months, not days.
For a deeper look at how Google ranks content in AI Overviews specifically, see the AI Overviews ranking guide.
What Actually Works, and Three Things That Do Not
What moves citations
Original research is the single highest-value asset for GEO. Content built on first-party data, surveys, benchmarks, and proprietary datasets has 5.2x the citation probability of synthesized content, per the Princeton GEO study. AI systems are built to cite authoritative, verifiable, data-backed material. First-party data gives them something no synthesized post can.
Entity clarity is the infrastructure layer. Andrea Volpini, CEO of WordLift, published research in March 2026 (arXiv:2603.10700, “Structured Linked Data as a Memory Layer for Agent-Orchestrated Retrieval”) testing a specific approach: rather than hiding your knowledge graph in JSON-LD that AI systems parse at index time, surface it as navigable, human-readable content. That means entity pages with explicit internal links between related entities, properties stated in natural language, and contextual instructions that guide AI interpretation. Across four industries, this approach improved retrieval system accuracy by 29.8%.
Volpini frames GEO readiness as a three-level ladder.
- Level 1 is Citations: can AI retrieve your content?
- Level 2 is Reasoning: can AI extract and relate facts accurately?
- Level 3 is Actions: can autonomous agents execute tasks using your content?
Most sites are still working on Level 1. Level 2 requires the knowledge graph layer. Level 3 is agentic, where content responds to AI agents acting on behalf of users rather than humans reading pages.
Myth 1: Adding schema will get you cited
Ahrefs ran the most controlled test on this question to date. They tracked 1,885 web pages that added JSON-LD schema between August 2025 and March 2026, matched against 4,000 control pages with similar pre-treatment citation levels that never added schema. The findings: Google AI Overviews showed a -4.6% change relative to controls (statistically significant), Google AI Mode +2.2% (not significant), ChatGPT +2.4% (not significant).
The surface read is “schema doesn’t work.” The sharper analysis came from Gianluca Fiorelli, a strategic SEO consultant who pointed out the study’s critical scope limitation: every page in the test already had 100+ AI Overview citations before treatment. In his words, it is “like testing whether adding a label to a bottle already on the supermarket shelf makes customers pick it up more often.” The study measured whether schema increases citations for already-visible pages. It did not measure whether schema helps pages reach initial visibility, which is where schema’s actual work happens.
Schema works at index time: entity parsing, Knowledge Graph construction, disambiguation. It does not fire at the moment of query retrieval. The Ahrefs study also pooled content schema (Article, FAQ, HowTo) with entity-identity schema (Organization) together, conflating two types that serve completely different purposes.
The honest guidance: do not add schema expecting a citation spike. Do have Organization schema in place as entity infrastructure, because it shapes how AI systems understand what your organization is across all pages, not just what any single page says.
Myth 2: Serve markdown to AI crawlers
In June 2026, Google Search Advocate John Mueller responded on Bluesky to a tactic spreading in technical SEO circles: using middleware to detect AI user agents and serve a stripped-down markdown version of pages instead of normal HTML. Mueller called it “a stupid idea.” His specific objections: AI crawlers do not recognize markdown as anything other than plain text. Links may not be followed correctly. Internal navigation, headers, and footers disappear. If AI companies wanted specific formats, they would request them openly.
Serve your normal HTML. The signal is in the content and structure, not the file format.
Myth 3: llms.txt is your AI search signal
Google confirmed in July 2025 that it does not process llms.txt and has no plans to. No major LLM provider (OpenAI, Anthropic, Google, Meta, Mistral) has publicly committed to using it as a production ranking or citation signal. An analysis of over 515 million LLM bot traffic events found that requests touching /llms.txt are statistically negligible.
Mike King argues that Claude reads llms.txt and that it is useful for developer documentation platforms. Stripe, Vercel, Cloudflare, and Supabase all have it. For SaaS companies with developer audiences, it is a reasonable crawl-access signal worth implementing. For most marketing sites, it is not a meaningful AI citation lever right now.
The Emerging Standards Layer
Most GEO guides in the current SERP were written before two things happened: the Ahrefs schema study, which reframed what structured data actually does, and EntityMap, which offers a more direct answer to the problem schema was always trying to solve.
EntityMap
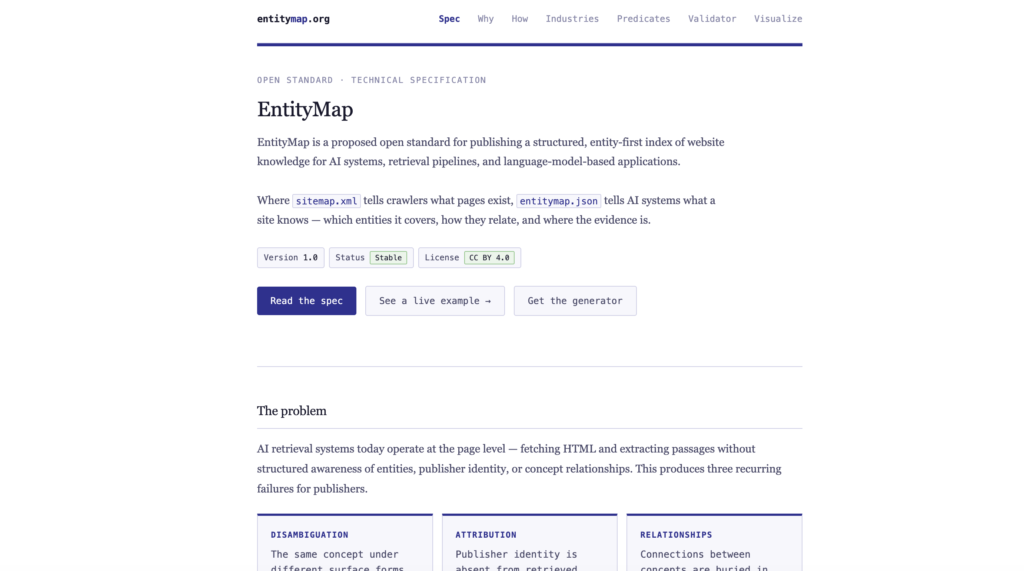
EntityMap is an open standard authored by Fred Laurent and Dixon Jones. Jones wrote Entity SEO: Moving from Strings to Things and has been working on entity-based search longer than most people in the GEO conversation. The standard reached v1.0 stable status on April 7, 2026. Public consultation runs through June 30, 2026, with formal launch on July 1.
Organizations publish a root-level JSON file at their domain containing three elements: named entities (products, services, people, locations), typed relations between those entities, and evidence chunks linked back to source URLs with attribution metadata. Where schema.org annotates individual pages, EntityMap operates at the organizational level. It tells AI systems what your organization is, what it knows, and how that knowledge connects across your entire site, rather than leaving AI systems to reconstruct that picture by stitching together fragments from multiple pages probabilistically. The result is fewer hallucinated product names, invented executives, and misquoted capabilities in AI-generated answers about your brand.
The standard defines three trust levels: generator-draft (AI-generated, not yet human-reviewed), self-declared (reviewed and approved by the organization), and third-party-verified (certified by the EntityMap registry, launching Q3 2026).
The only published case study comes from Waikay, which deployed an entitymap on April 25, 2026 and measured AI Knowledge Scores through June 1. On Gemini and Sonar/Perplexity, the entitymap was cited 2.2 to 3.0x more often than the site’s own About page: 6.5% citation share on Gemini versus 3.0% for the About page. One tracked topic improved 26 Knowledge Score points within 48 hours of deployment.
I deployed EntityMap on michaelpatrickcortez.com in early June 2026 and have been running the same measurement. Bing AI citations: 86 in June versus 92 at end of May, no discernible lift. That tracks with the Waikay team’s own caveat that Bing had not indexed their entitymap file by the time their study closed. The Gemini and Perplexity data will take more time to collect systematically. It is too early to draw conclusions, but the Waikay numbers are worth taking seriously.
The agentic RAG shift
Mike King’s most important recent work, published at iPullRank in 2026, addresses a structural shift in how AI retrieval systems work that most GEO guides have not caught up to. The first wave of AI search used single-shot RAG: a query triggers one retrieval, yields top-k passages, feeds them to an LLM, generates an answer. That pattern is obsolete in production systems.
Current systems use what King calls agentic RAG. RAG stands for Retrieval-Augmented Generation: instead of answering from training data alone, the system retrieves relevant passages from the web and feeds them into the language model before generating a response. In agentic RAG, that retrieval process happens in multiple rounds with a planning layer directing it. Four properties define it: planning (decomposing queries into 5 to 20 sub-queries before any retrieval begins), tool use (the system routes between different retrieval methods depending on what each sub-query needs), multi-hop iteration (agents retrieve, evaluate what they found, then retrieve again based on what they learned), and reflection (a critic layer grades draft answers and re-queries if quality fails).
King’s implication: you are no longer optimizing for one retrieval event. You are competing across many sub-retrievals simultaneously. His six content strategy shifts for agentic RAG: write atomic passages (self-contained, scoped chunks that win pairwise comparisons against competitors), build bridge entities (position your content as the canonical source on the relationship between two entities for multi-hop retrieval), create reflection resilience (address counterarguments and edge cases so the critic layer does not filter you out), build tool surfaces where applicable (calculators or APIs for domains where tools outperform prose), signal freshness explicitly (dateModified, version numbers, “as of” framing), and expand topical breadth rather than depth on single keywords.
His measurement point is the hardest to accept: citation counts underreport actual AI footprint by 3 to 10x in agentic systems, per his published analysis of agentic retrieval pipelines. Most retrieval happens in sub-queries that never surface in the final cited sources list. You may be influencing AI answers significantly without seeing it in any citation tracking tool.
A Claude Code Workflow to Audit Your GEO Gap
Most GEO audits I see are manual: someone opens ChatGPT, types a few queries, checks if their brand shows up, and calls it an audit. That is a spot check. It tells you nothing about patterns, scale, or what to fix first.
Here is an agent-native workflow in Claude Code that turns this into a systematic, repeatable process.
Step 1: Pull your top impression keywords from GSC.
In Claude Code with the Ahrefs MCP connected, run:
mcp__claude_ai_ahrefs__gsc-keywordsThis returns your top GSC keywords by impression volume. These are the queries where you have topical relevance in Google’s index but are not necessarily winning clicks. They are your highest-priority GEO test candidates because the question is not whether you are relevant (Google already confirmed that) but whether that relevance is translating to AI citation.
Save the output to a file: geo-gap-audit/gsc-keywords.json
Step 2: Run parallel citation checks across platforms.
In Claude Code, set up a parallel subagent structure where three agents run simultaneously:
Agent 1: WebSearch each keyword on Google, log whether your domain appears in the AI Overview panel
Agent 2: WebSearch each keyword on Bing, log whether your domain appears in Bing AI citations
Agent 3: Flag keywords for manual Perplexity check via Otterly.ai or direct Perplexity queryA note on Perplexity: Claude Code’s WebSearch tool searches Google and Bing, not Perplexity directly. For Perplexity citation data, use a dedicated tool like Otterly.ai, or run a manual query batch in Perplexity for your top 10-20 priority keywords. The agent writes a list of keywords flagged for manual Perplexity review so nothing falls through.
Three agents running in parallel means a 50-keyword audit that would take 15+ sequential minutes completes in under 5. Each agent writes results directly to geo-gap-audit/citations-[platform].json. No copy-paste, no manual logging.
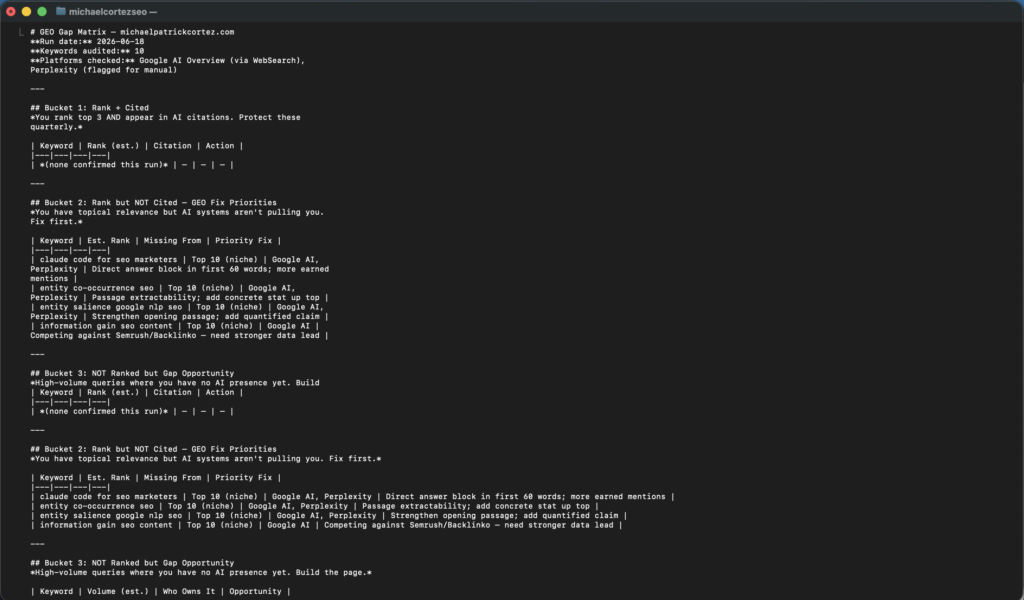
Step 3: Build the gap matrix and schedule weekly monitoring.
Claude Code reads the output files and compiles a citation gap matrix with keywords bucketed into three groups.
Bucket 1: You rank top 3 and get cited. Protect these by refreshing content quarterly and keeping entity signals clean.
Bucket 2: You rank but are not cited. These are your GEO fix priorities. Start with passage structure (direct answer block in the first 60 words), then entity clarity, then earned media placement.
Bucket 3: You are cited but do not rank. You have an authority signal already. Build the landing page to capture the click.
Add a CLAUDE.md entry with your target keywords and audit file paths, then run:
/loop 7d /geo-gap-auditClaude Code re-runs the full audit weekly, appends to a running log, and flags any keyword that moves between buckets. The workflow is saved as a permanent skill at .claude/skills/geo-gap-audit/SKILL.md and invoked with /geo-gap-audit at the start of any week without rebuilding from scratch.
For the full framework on measuring AI search visibility over time, the AI search visibility post covers the metric layer in more detail.
The Zero-Click Conversion Argument
The concern about zero-click search is real but usually framed wrong. The frame should not be “AI is taking my traffic.” It should be: the traffic that survives is worth more, and brand citations without clicks still generate measurable downstream value.
Sites cited in AI answers earn 35% higher organic CTR and 91% higher paid CTR compared to uncited brands, per a Seer Interactive study of 3,119 informational queries across 42 organizations (November 2025). The brand impression from an AI citation drives recall and later conversion even without a direct click. Clicks that do survive an AI Overview convert 23% better than standard organic clicks. AI-driven traffic overall converts at 4.4x the traditional organic average.
The new valuation model for GEO visibility is not sessions or clicks. It is citation frequency multiplied by brand recall factor multiplied by downstream conversion rate. That rewards brands cited consistently over brands that rank highly for queries that no longer drive clicks to begin with.
For the broader strategic framework on LLM search visibility, this fits into the full picture covered in the LLM SEO pillar.
Frequently Asked Questions
Is GEO replacing SEO?
No. They serve different user behaviors and different intent categories. Transactional and local queries still resolve through traditional search, and Google still processes 8.5 billion queries per day. GEO has become essential for informational and research-intent queries, where AI systems now synthesize answers rather than serve a results page. Most sites need both, with different tactics and different success metrics for each.
Does ranking number one on Google guarantee AI Overview inclusion?
No. By early 2026, only 38% of AI Overview citations came from pages in the top 10 organic results for the same query, per BrightEdge research. 47% came from pages ranking below position five. The signals that predict AI citation overlap with traditional ranking signals but are not identical, with entity clarity, original data, passage extractability, and earned media carrying more weight than link volume alone.
Does schema markup help with AI citations?
Adding schema to pages that already have AI citation visibility does not appear to meaningfully increase those citations. The Ahrefs controlled study of 1,885 pages found no statistically significant lift, and AI Overviews showed a slight decline. But as Gianluca Fiorelli noted, that study only measured already-cited pages, not the earlier-stage effect of schema on indexation and entity disambiguation. Schema works at index time, not at retrieval time. Organization schema in particular is worth having in place because it shapes how AI systems understand what your organization is across your entire site.
What is EntityMap and do I need it?
EntityMap is an open standard (formal launch July 1, 2026) that lets organizations publish a root-level JSON file declaring their entities, typed relationships, and source-attributed evidence. Where schema.org annotates individual pages, EntityMap operates at the organizational level. The only published case study (Waikay, April-June 2026) showed 2.2 to 3.0x citation improvement on Gemini and Perplexity versus the site’s own About page. Results on Bing-dependent platforms are still pending indexation. I am testing it on this site now with no discernible Bing AI lift yet after a few weeks, which matches the Waikay team’s own early data. Worth implementing since it takes under an hour, but verify results on your own platforms before drawing conclusions.
How is GEO different from AEO?
Answer Engine Optimization (AEO) focuses specifically on earning featured snippets, People Also Ask placements, and voice search responses in traditional Google results. GEO covers optimization for any AI-generated response, including AI Overviews, ChatGPT, Perplexity, Claude, and emerging agentic surfaces. AEO is one component of GEO, specifically the Google Search layer. GEO additionally requires thinking about earned media, entity identity across platforms, and multi-platform citation measurement that AEO does not address. For the AEO layer specifically, see the answer engine optimization guide.
How do I measure GEO performance?
The tool landscape is still developing. Practical approaches right now: track branded search volume in GSC as a proxy for brand recall driven by AI citations, monitor direct traffic trends alongside citation activity, use tools like Otterly.ai for platform-level citation monitoring, and run the weekly Claude Code gap audit described above. The deeper problem King identifies is that agentic RAG systems underreport actual AI footprint by 3 to 10x, because citation counts do not capture sub-query retrievals. Combine citation tracking with downstream brand signal metrics rather than treating citation count alone as the full picture.
What to Do Next
If you want to start with a data-backed look at where your site stands across Google AI Overviews, ChatGPT, and Perplexity, Search Clarity connects to your GSC data and surfaces the queries where you have impressions but no citations. Those are your highest-priority GEO opportunities.
For the broader AI search strategy, the generative engine optimization guide covers the full GEO framework, and the ChatGPT citation guide goes deeper on the platform-specific mechanics for that platform in particular.